Fixed File Input
- Former user (Deleted)
- Former user (Deleted)
- Former user (Deleted)
- Former user (Deleted)
Description
This step is used to read data from a fixed-width text file, exclusively. In fixed-width files, the format is specified by column widths, padding, and alignment. Column widths are measured in units of characters. For example, the data in the file contains a first column that has exactly 12 characters, and the second column has exactly 10, the third has exactly 7, and so on. Each row contains one record of information; each record can contain multiple pieces of data (fields), each data field (column) has a specific number of characters. When the data does not use all the characters alloted to it, the data is padded with spaces (or other character). In addition, each data element may be left or right justified, which means that characters can be padded on either side.
A sample Fixed File Input transformation is located at :
...\samples\transformations\Fixed Input - fixed length reading .kt
This step has fewer overall options than the general Text File Input step, but it has a few advantages over it:
- NIO -- Native system calls for reading the file means faster performance, but it is limited to only local files currently. No VFS support.
- Parallel running -- If you configure this step to run in multiple copies or in clustered mode, and you enable parallel running, each copy will read a separate block of a single file allowing you to distribute the file reading to several threads or even several slave nodes in a clustered transformation.
- Lazy conversion -- If you will be reading many fields from the file and many of those fields will not be manipulate, but merely passed through the transformation to land in some other text file or a database, lazy conversion can prevent Kettle from performing unnecessary work on those fields such as converting them into objects such as strings, dates, or numbers.
For information on valid date and numeric formats used in this step, view the Date Formatting Table and the Number Formatting Table.
Options
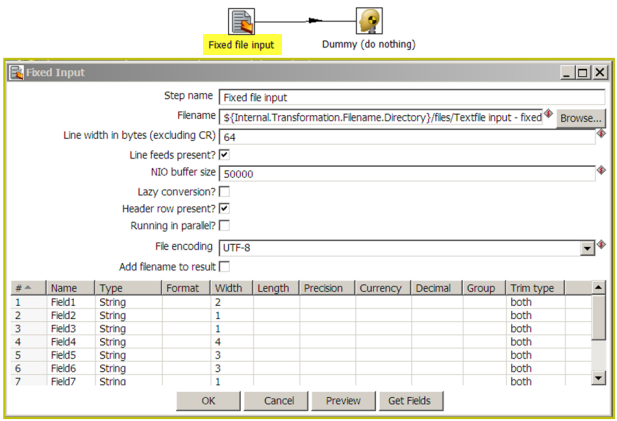
The table below describes the options available for the Fixed File Input step:
Option | Description |
|---|---|
Step name | Name of the step.
|
Filename | Specify the name of the CSV file to read from. |
Line width in bytes | Specify the width of each record in the target file. This is the width excluding the carriage return or linefeed fields. |
Line feeds present? | Check if the target file contains line feed characters. |
NIO buffer size | This is the size of the read buffer. It represents the amount of bytes that is read in one time from disk. |
Lazy conversion | The lazy conversion algorithm will try to avoid unnecessary data type conversions and can result in a significant performance improvements if this is possible. The typical example that comes to mind is reading from a text file and writing back to a text file. Check to enable. |
Header row present? | Enable this option if the target file contains a header row containing column names. |
Running in parallel? | Check this box if you will have multiple instances of this step running (step copies) and if you want each instance to read a separate part of the file. |
File Encoding | Specify the encoding of the file being read. |
Add filename to result | Adds the filename(s) read to the result of this transformation. A unique list is being kept in memory that can be used in the next job entry in a job, for example in another transformation. |
Fields Table | This table contains an ordered list of fields to be read from the target file. |
Preview button | Click to preview the data coming from the target file. |
Get Fields button | Click to return a list of fields from the target file based on the current settings (i.e. Delimiter, Enclosure, etc.). All fields identified will be added to the Fields Table. |
Metadata Injection Support
You can use the Metadata Injection supported fields with ETL Metadata Injection step to pass metadata to your transformation at runtime. The following Option and Value fields of the Fixed File Input step support metadata injection:
- Options: Filename, Line Width in Bytes, Line Feeds Present?, NIO Buffer Size, Lazy Conversion, Header Row Present?, Running in Parallel?, File Encoding, and Add Filename to Result
- Values: Name, Precision, Type, Currency, Format, Decimal, Width, Group, Length, and Trim Type