Dimension Lookup-Update
Description
The Dimension Lookup/Update step allows you to implement Ralph Kimball's slowly changing dimension for both types: Type I (update) and Type II (insert) together with some additional functions.
Not only can you use this step to update a dimension table, it may also be used to look up values in a dimension.
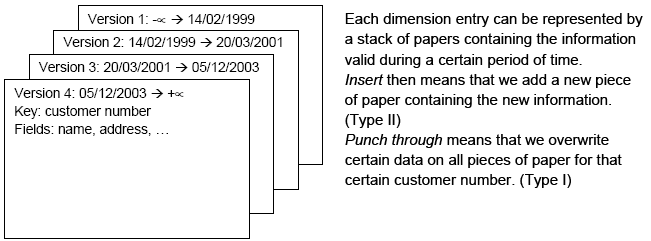
In this dimension implementation each entry in the dimension table has the following properties:
Option |
Description |
|---|---|
Technical key |
This is the primary key of the dimension. |
Version field |
Shows the version of the dimension entry (a revision number). |
Start of date range |
This is the field name containing the validity starting date. |
End of date range |
This is the field name containing the validity ending date. |
Keys |
These are the keys used in your source systems. For example: customer numbers, product id, etc. |
Fields |
These fields contain the actual information of a dimension. |
As a result of the lookup or update operation of this step type, a field is added to the stream containing the technical key of the dimension. In case the field is not found, the value of the dimension entry for not found (0 or 1, based on the type of database) is returned.
Note: This dimension entry is added automatically to the dimension table when the update is first run. If you have "NOT NULL" fields in your table, adding this empty row and then the entire step will fail! So make sure that you have a record with the ID field = 0 or 1 in your table if you don't want PDI to insert a potentially invalid empty record.
A number of optional fields (in the "Fields" tab) are automatically managed by the step. You can specify the table field name in the "Dimension Field" column. These are the optional fields:
- Date of last insert or update (without stream field as source) : adds and manges a Date field
- Date of last insert (without stream field as source) : adds and manges a Date field
- Date of last update (without stream field as source) : adds and manges a Date field
- Last version (without stream field as source) : adds and manges a Boolean field. (converted into Char(1) or boolean database data type depending on your database connection settings and availability of such data type)
This acts as a current valid dimension entry entry indicator for the last version: So when a type II attribute changes and a new version is created (to keep track of the history) the 'Last version' attribute in the previous version is set to 'False/N' and the new record with the latest version is set to 'True/Y'.
Functionality
As the name of the step suggests, the functionality of the step falls into 2 categories, Lookup and Update...
Lookup
In read-only mode (update option is disabled), the step only performs lookups in a slowly changing dimension. The step will perform a lookup in the dimension table on the specified database connection and in the specified schema. To do the lookup it uses not only the specified natural keys (with an "equals" condition) but also the specified "Stream datefield" (see below). The condition that is applied is:
"Start of table date range" <= "Stream datefield" AND "End of table date range" > "Stream datefield"
When no "Stream datefield" is specified we use the current system date to find the correct dimension version record.
Note: If you use an "alternative start date" the SQL clause described above will differ slightly.
When no row is found, the "unknown" key is returned. (The "unknown" key will be 0 or 1 depending on whether or not you selected an auto-increment field for the technical key field). Please note that we don't make a difference between "Unknown", "Not found", "Empty", "Illegal format", etc. These nuances can be added manually however. Nothing prevents you from flushing out these types before the data hits this step with a Filter, regular expression, etc. We suggest you manually add values -1, -2, -3, etc for these special dimension entry cases, just like you would add the specific details of the "Unknown" row prior to population of the dimension table.
Important: Because SQL is used to look up the technical key in the dimension table, take the following precautions:
- Do not use NULL values for your natural key(s). Null values can't be compared and are not indexed by most databases. Even if we would support null values in keys (something that doesn't make a lot of sense anyway), it would most likely cause severe lookup performance problems.
- Be aware of data conversion issues that occur if you have data types in your input streams that are different from the data types in your natural key(s). If you are have Strings in the steps input and in the database you use an Integer for example, make sure you are capable of converting the String to number. See it as a best practice to do this before this step to make sure it works as planned. Another typical example of problems is with floating point number comparisons. Stay away from those. We recommend you use sane data types like Integer or long integers. Stay away from Double, Decimal or catch-all data types like Oracle's Number (without length or precision; it implicitly uses precision 38 causing us to use the slower BigNumber data type).
Update
In update mode (update option is enabled) the step first performs a lookup of the dimension entry as described in the "Lookup" section above. The result of the lookup is different though. Not only the technical key is retrieved from the query, but also the dimension attribute fields. A field-by-field comparison then follows. The result can be one of the following situations:
- The record was not found, we insert a new record in the table.
- The record was found and any of the following is true:
- One or more attributes were different and had an "Insert" (Kimball Type II) setting: A new dimension record version is inserted.
- One or more attributes were different and had a "Punch through" (Kimbal Type I) setting: These attributes in all the dimension record versions are updated.
- One or more attributes were different and had an "Update" setting: These attributes in the last dimension record version are updated.
- All the attributes (fields) were identical: No updates or insertions are performed.
- Insertion of new rows are performed in the following steps:
- The current row is updated with "date_to" updated with the "Stream date field"
- The new row is inserted where the changes in attributes are recorded according to rule in previous paragraph. "date_from" field is updated with the "Stream date field" and the "date_to" is updated with the Max date of the table range end date.
- The version number of the new row in incremented by 1.
- "Stream date field" cannot be before the earliest start date of the currently valid rows.
select min(date_from) from dim_table where date_to = "2199-12-31 23:59:59.999"
- It is important to ensure that the incoming rows are sorted by the "Stream date field"
Note: If you mix Insert, Punch Through and Update options in this step, this algorithm acts like a Hybrid Slowly Changing Dimension. (it is no longer just Type I or II, it is a combination)
Options
The following table provides a more detailed description of the options for the Dimension Lookup/Update step:
Option |
Description |
|---|---|
Step name |
Name of the step.
|
Update the dimension? |
Enable to update the dimension based on the information in the input stream; if not enabled, the dimension only performs lookups and adds the technical key field to the streams. |
Connection |
Name of the database connection on which the dimension table resides. |
Target schema |
This allows you to specify a schema name. |
Target table |
Name of the dimension table. |
Commit size |
Define the commit size, e.g. setting commit size to 10 generates a commit every 10 inserts or updates. |
Caching |
|
Keys tab |
Specify the names of the keys in the stream and in the dimension table. This will enable the step to perform the lookup. |
Fields tab |
For each of the fields you must have in the dimension, you can specify whether you want the values to be updated (for all versions, this is a Type I operation) or you want to have the values inserted into the dimension as a new version. In the example we used in the screenshot the birth date is something that's not variable in time, so if the birth date changes, it means that it was wrong in previous versions. It's only logical then, that the previous values are corrected in all versions of the dimension entry. |
Technical key field |
The primary key of the dimension; also referred to as Surrogate Key. Use the new name option to rename the technical key after a lookup. For example, if you need to lookup different types of products like ORIGINAL_PRODUCT_TK, REPLACEMENT_PRODUCT_TK, ...
|
Creation of technical key |
Indicates how the technical key is generated, options that are not available for your connection type will be grayed out:
|
Version field |
The name of the field in which to store the version (revision number). |
Stream Datefield |
If you have the date at which the dimension entry was last changed, you can specify the name of that field here. It allows the dimension entry to be accurately described for what the date range concerns. If you don't have such a date, the system date will be taken. |
Date range start field |
Specify the names of the dimension entries start range. |
Use an alternative start date? |
When enabled, you can choose an alternative to the "Min. Year"/01/01 00:00:00 date that is used. You can use any of the following:
|
Table date range end |
The names of the dimension entries end range |
Get Fields button |
Fills in all the available fields on the input stream, except for the keys you specified. |
SQL button |
Generates the SQL to build the dimension and allows you to execute this SQL. |
Metadata Injection Support
All fields of this step support metadata injection. You can use this step with ETL Metadata Injection to pass metadata to your transformation at runtime.
Remarks
- For the Stream date field: Consider adding an extra date field from System Info if you don't want the date ranges to be different all the time. For example if you have extracts from a source system being done every night at midnight, consider adding date "Yesterday 23:59:59" as a field to the stream by using a Join step.
Important: this needs to be a Date field. We isolate functionality and as such require you to do date type conversions in advance.
- For the "Date range start and end fields": You can only enter a year in these fields, not a timestamp. If you enter a year YYYY (e.g. 2100), it will be used as timestamp "YYYY-01-01 00:00:00.00" for start date and "YYYY-12-31 23:59:59.999" for end date in the dimension table.
- Late arriving data: The step does not support late arriving data. At this time you need to sort records by reference date.
- Select currently valid rows: Select rows with end date the same as the Table date range end Max date. Example below.
where date_to = "2199-12-31 23:59:59.999"