.03 Database Connections
Database Connections
A database connection describes the method by which Kettle connects to a database. You can create connections specific to a Job or Transformation or store them in the Kettle repository for re-use in multiple transformations or jobs.
Note: Please see also Special database issues and experiences
The following topics are covered in this section:
- #Creating a New Database Connection
- #Editing a Connection
- #Duplicating a Connection
- #Copying to a Clipboard
- #Deleting a Connection
- #Executing SQL Commands on a Connection
- #Clearing the Database Cache Option
- #Quoting
- #Database Usage Grid
- #Configuring JNDI Connections
- #Unsupported Databases
Creating a New Database Connection
This section describes how to create a new database connection and includes a detailed description of each connection property available in the Connection information dialog box.
To create a new connection right click the Database Connections in the tree and select New or New Connection Wizard. You can also double click Database Connections, or press F3.
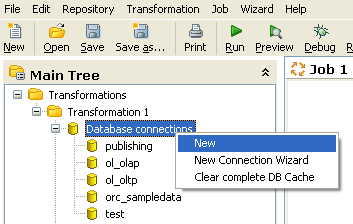
The Connection information dialog box appears. The topics that follow describe the configuration options available on each tab of the Connection information dialog box.
General
The general tab is where you set up the basic information about your connection such as the connection name, type, access method, server name and log on credentials. The table below provides a detailed description of the options available under the General tab:
Feature |
Description |
|---|---|
Connection Name |
Uniquely identifies a connection across transformations and jobs |
Connection Type |
Type of database you are connecting to (for example, MySQL, Oracle, and so on) |
Method of access |
This will be either Native (JDBC), ODBC, or OCI. Available access types depend on the type of database you are connecting to |
Server host name |
Defines the host name of the server on which the database resides. You can also specify the host by IP-address |
Database name |
Identifies the database name you want to connect to. In case of ODBC, specify the DSN name here |
Port number |
Sets the TCP/IP port number |
Username |
Optionally specifies the user name to connect to the database |
Password |
Optionally specifies the password to connect to the database |
Pooling
The pooling tab allows you to configure your connection to use connection pooling and define options related to connection pooling like the initial pool size, maximum pool size and connection pool parameters. The table below provides a more detailed description of the options available on the Pooling tab:
Feature |
Description |
|---|---|
Use a connection pool |
Enables connection pooling |
The initial pool size |
Sets the initial size of the connection pool. |
The maximum pool size. |
Sets the maximum number of connections in the connection pool. |
Parameter Table |
Allows you to define additional custom pool parameters. |
MySQL
By default, MySQL returns complete query results in one block to the client, (Kettle in this case), so "result streaming" is enabled. One drawback associated result streaming is that it allows only one single query to be opened at any given time. You can disable this option in the MySQL tab of the database connection dialog box if necessary.
Another issue you may encounter is that the default timeout in the MySQL JDBC driver is set to 0 (no timeout). In certain instances, this may not allow Kettle to detect a server crash or sudden network failure if it occurs in the middle of a query or open database connection. This in turn leads to the infinite stalling of a transformation or job. To solve problem, set the "connectTimeout" and "socketTimeout" parameters for MySQL in the Options tab. The value to be specified is in milliseconds: for a 2 minute timeout you would specify value 120000 ( 2 x 60 x 1000 ).
You can also review other options on the linked MySQL help page by clicking on the 'Show help text on option usage' button found on the Options tab.
Note: please see also MySQL
Oracle
This tab allows you to specify the default data and index tablespaces which Kettle uses when generating SQL for Oracle tables and indexes.
This version of Pentaho Data Integration ships with the Oracle JDBC driver version 10.2.0. It is the most stable and recent driver we could find; however, if you have issues with Oracle connectivity or other problems, you may consider replacing the 10.2. JDBC driver to match your database server. Replace files "ojdbc14.jar" and "orai18n.jar" in the directory libext/JDBC of your distribution with the files found in the $ORACLE_HOME/jdbc directory on your server.
If you are using OCI and an Oracle Net8 client, the JDBC driver version used in Kettle needs to match your Oracle client version. PDI 2.5.0 shipped with version 10.1, 3.0.0 ships with version 10.2. You can either install that version of the Oracle client or change the JDBC driver in PDI if versions don't match up.
Note: please see also Oracle
Informix
For Informix, you must specify the Informix Server name in the Informix tab in order for a connection to be usable.
SQL Server
This tab allows you configure the following properties specific to Microsoft SQL Server:
Feature |
Description |
|---|---|
SQL Server instance name |
Sets the instance name property for the SQL Server connection. |
Use .. to separate schema and table |
Enable when using dot notation to separate schema and table. |
Other properties can be configured by adding connection parameters on the options tab of the Connection information dialog box. For example, you can enable single sign-on login by defining the domain option on the Options tab as shown below:
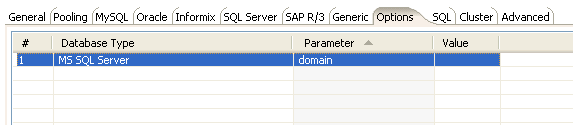
From the jTDS FAQ on http://jtds.sourceforge.net/faq.html:
Specifies the Windows domain to authenticate in. If present and the user name and password are provided, jTDS uses Windows (NTLM) authentication instead of the usual SQL Server authentication (i.e. the user and password provided are the domain user and password). This allows non-Windows clients to log in to servers which are only configured to accept Windows authentication.
If the domain parameter is present but no user name and password are provided, jTDS uses its native Single-Sign-On library and logs in with the logged Windows user's credentials"
Note: please see also MS SQL Server
SAP R/3
This tab allows you configure the following properties specific to SAP R/3:
Feature |
Description |
|---|---|
Language |
Specifies the language to be used when connecting to SAP. |
System Number |
Specifies the system number of the SAP system to which you want to connect. |
SAP Client |
Specifies the three digit client number for the connection. |
Note: For this to work, you need a plug-in, please see List of Available Pentaho Data Integration Plug-Ins
Generic
This tab is where you specify the URL and Driver class for Generic Database connections. You can also dynamically set these properties using Kettle variables. Using Kettle variables provides you with the ability to access data from multiple database types using the same transformations and jobs.
Note: Make sure to use clean ANSI SQL that works on all used database types in the latter case.
Options
This tab allows you to set database-specific options for the connection by adding parameters to the generated URL.
The use of variables is also possible within the Paramater / Value options.
Follow the instructions below to add a parameter:
- Select the next available row in the parameter table
- Choose your database type and enter a valid parameter name and its corresponding value
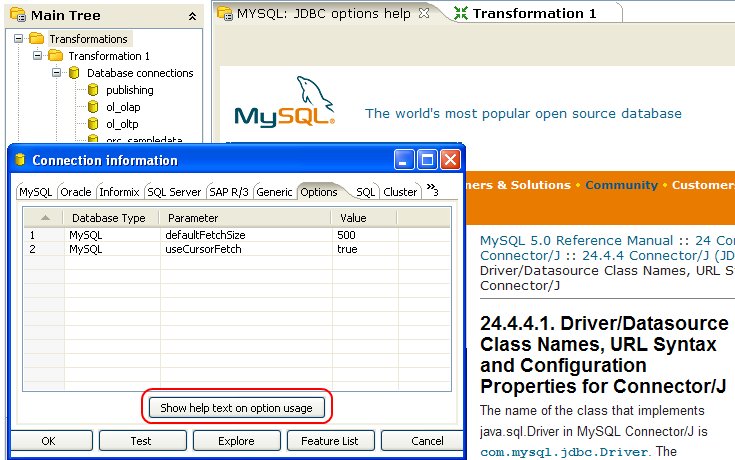
- For more database-specific configuration help, click the 'Show help text on option usage' button and a new browser tab appears in Spoon with additional information about the configuring the JDBC connection for the currently selected database type:
SQL
This tab allows you to enter a number of SQL commands immediately after connecting to the database. This is sometimes needed for reasons such as licensing, configuration, logging, tracing, and so on.
Cluster
This tab allows you to enable clustering for the database connection and create connections to the data partitions. To enable clustering for the connection, enable the 'Use Clustering?' option.
To create a new data partition, enter a partition ID and the hostname, port, database, username and password for connecting to the partition.
Advanced
This tab allows you configure the following properties for the connection:
Feature |
Description |
|---|---|
Quote all identifiers in database |
Specifies the language to be used when connecting to SAP |
Force all identifiers to lower case |
Specifies the system number of the SAP system to which you want to connect |
Force all identifiers to upper case |
Specifies the three digit client number for the connection |
Testing a Connection
The Test button in the Connection information dialog box allows you to test the current connection. An confirmation message displays if Spoon is able to establish a connection with the target database.
Explore
The Database Explorer allows you to browse the target database interactively, preview data, generate DDL and much more. To open the Database Explorer for an existing connection, click the 'Explore' button found on the Connection information dialog box or right-click on the connection in the Main tree and select 'Explore'. See the Database Explorer for more information.
Feature List
The feature list exposes the JDBC URL, class, and various database settings for the connection such as the list of reserved words.
Editing a Connection
To edit an existing connection, double-click on the connection name in the main tree or right-click on the connection name and select 'Edit connection.'
Duplicating a Connection
To duplicate an existing connection, right-click on the connection name and select Duplicate.
Copying to a Clipboard
This option allows you to copy the XML defining the step to the clipboard. You can then paste this step into another transformation.
Deleting a Connection
To delete an existing database connection, right-click on the connection name in the main tree and select Delete.
Executing SQL Commands on a Connection
To execute SQL command against an existing connection, right-click on the connection name and select SQL Editor. See the SQL Editor for more information.
Clearing the Database Cache Option
To speed up connections Spoon uses a database cache. When the information in the cache no longer represents the layout of the database, right-click on the connection in the Main tree and select the 'Clear DB Cache...' option. This command is commonly used when databases tables have been changed, created or deleted.
Quoting
Pentaho has implemented a database-specific quoting system that allows you to use any name or character acceptable to the supported databases' naming conventions.
Pentaho Data Integration contains a list of reserved words for most of the supported databases. To ensure that quoting behaves correctly, Pentaho has implemented a strict separation between the schema (user/owner) of a table and the tablename itself. Doing otherwise, makes it impossible to quote tables or fields with one or more periods in them correctly. Placing periods in table and field names is common practice in some ERP systems(for example, fields such as "V.A.T.")
To avoid quoting-related errors, Pentaho has added a new rule in version 2.5.0 that stops the Pentaho Data Integration from performing quoting activity when there is a start or end quote in the tablename or schema. This allows you to specify the quoting mechanism yourself.
Note: Contact Pentaho if you find other ways to improve Pentaho's quoting algorithms.
Database Usage Grid
The table below contains information that may help you configure your particular database.
Note: The list of supported databases grows continuesly in each release. Please see the list of Connection types in the database dialog.
Database |
Access Method |
Server Name or IP Address |
Database Name |
Port # (default) |
User Name and Password |
|---|---|---|---|---|---|
Oracle |
Native |
Required |
Oracle database SID |
Required (1521) |
Required |
|
ODBC |
|
ODBC DSN name |
|
Required |
|
OCI |
|
Database TNS name |
|
Required |
MySQL |
Native |
Required |
MySQL database name |
Optional (3306) |
Optional |
|
ODBC |
|
ODBC DSN name |
|
Optional |
AS/400 |
Native |
Required |
AS/400 Library name |
Optional |
Required |
|
ODBC |
|
ODBC DSN name |
|
Required |
MS Access |
ODBC |
|
ODBC DSN name |
|
Optional |
MS SQL Server |
Native |
Required |
Database name |
Required (1433) |
Required |
|
ODBC |
|
ODBC DSN name |
|
Required |
IBM DB2 |
Native |
Required |
Database name |
Required (50000) |
Required |
|
ODBC |
|
ODBC DSN name |
|
Required |
PostgreSQL |
Native |
Required |
Database name |
Required (5432) |
Required |
|
ODBC |
|
ODBC DSN name |
|
Required |
Intersystems Caché |
Native |
Required |
Database name |
Required (1972) |
Required |
|
ODBC |
|
ODBC DSN name |
|
Required |
Sybase |
Native |
Required |
Database name |
Required(5001) |
Required |
|
ODBC |
|
ODBC DSN name |
|
Required |
Gupta SQL Base |
Native |
Required |
Database Name |
Required (2155) |
Required |
|
ODBC |
|
ODBC DSN name |
|
Required |
Dbase III,IV or 5.0 |
ODBC |
|
ODBC DSN name |
|
Optional |
Firebird SQL |
Native |
Required |
Database name |
Required (3050) |
Required |
|
ODBC |
|
ODBC DSN name |
|
Required |
Hypersonic |
Native |
Required |
Database name |
Required (9001) |
Required |
MaxDB (SAP DB) |
Native |
Required |
Database name |
|
Required |
|
ODBC |
|
ODBC DSN name |
|
Required |
Ingres |
Native |
Required |
Database name |
|
Required |
|
ODBC |
|
ODBC DSN name |
|
Required |
Borland Interbase |
Native |
Required |
Database name |
Required (3050) |
Required |
|
ODBC |
|
ODBC DSN name |
|
Required |
ExtenDB |
Native |
Required |
Database name |
Required (6453) |
Required |
|
ODBC |
|
ODBC DSN name |
|
Required |
Teradata |
Native |
Required |
Database name |
|
Required |
|
ODBC |
|
ODBC DSN name |
|
Required |
Oracle RDB |
Native |
Required |
Database name |
|
Required |
|
ODBC |
|
ODBC DSN name |
|
Required |
H2 |
Native |
Required |
Database name |
|
Required |
|
ODBC |
|
ODBC DSN name |
|
Required |
Netezza |
Native |
Required |
Database name |
Required (5480) |
Required |
|
ODBC |
|
ODBC DSN name |
|
Required |
IBM Universe |
Native |
Required |
Database name |
|
Required |
|
ODBC |
|
ODBC DSN name |
|
Required |
SQLite |
Native |
Required |
Database name |
|
Required |
|
ODBC |
|
ODBC DSN name |
|
Required |
Apache Derby |
Native |
optional |
Database name |
Optional (1527) |
Optional |
|
ODBC |
|
ODBC DSN name |
|
Optional |
Generic |
Native |
Required |
Database name |
Required (Any) |
Required |
|
ODBC |
|
ODBC DSN name |
|
Optional |
The generic database connection also needs to specify the URL and Driver class in the Generic tab. Pentaho also allows these fields to be specified using a variable so you can access data from multiple database types using the same transformations and jobs. Make sure to use clean ANSI SQL that works on all used database types in that case.
Configuring JNDI Connections
If you are developing transformations and jobs that will be deployed on an application server such as the Pentaho platform running on JBoss, you can configure your database connections using JNDI.
Because you don't want to have an application server running all the time during development or testing of the transformations, Pentaho has supplied a way of configuring a JNDI connection for "local" Kettle use.
To configure, edit the properties file called "simple-jndi/jdbc.properties" For example, to connect to the databases used in Pentaho Demo platform download and use this information in the properties file:
SampleData/type=javax.sql.DataSource SampleData/driver=org.hsqldb.jdbcDriver SampleData/url=jdbc:hsqldb:hsql://localhost/sampledata SampleData/user=pentaho_user SampleData/password=password Quartz/type=javax.sql.DataSource Quartz/driver=org.hsqldb.jdbcDriver Quartz/url=jdbc:hsqldb:hsql://localhost/quartz Quartz/user=pentaho_user Quartz/password=password Hibernate/type=javax.sql.DataSource Hibernate/driver=org.hsqldb.jdbcDriver Hibernate/url=jdbc:hsqldb:hsql://localhost/hibernate Hibernate/user=hibuser Hibernate/password=password Shark/type=javax.sql.DataSource Shark/driver=org.hsqldb.jdbcDriver Shark/url=jdbc:hsqldb:hsql://localhost/shark Shark/user=sa Shark/password=
Note: It is important that the information stored in this file in the simple-jndi directory mirrors the content of your application server data sources.
Unsupported Databases
Contact Pentaho if you want to access a database type that is not yet supported. A few database types are not supported in this release due to the lack of a sample database and/or software.
It is generally possible to read from unsupported databases by using the Generic database driver through an ODBC or JDBC connection.