What's new in PDI version 3.2
Index
- #Introduction
- #General changes
- #Step changes
- #Job entry changes
- #Repository
- #Databases
- #Community and codebase
Introduction
When you compare this release to the previous one, you will see that the changes are more evolutionary, rather than revolutionary. Even so, there have been a large amount of changes for a minor version increase. The main focus of the release is once again stability and usability. We went through a large number of pet-peeves, common mis-understandings and simply solved them, either through new features or by modifying existing ones. On top of that we worked on the clustering side to make that mode "cloud-ready" with dynamic clustering, making it more solid, adding features too.
Once again, many many thanks go to our large community of Kettle enthusiasts for all the help they provided to make this release another success.
General changes
- Visual changes
- Hop color scheme with mini-icons, tooltips (note: tooltips not available on OSX currently)
 *** After running with errors : show error icons (note: error details tooltip not available on OSX currently)
*** After running with errors : show error icons (note: error details tooltip not available on OSX currently)
- Visual feedback : reading from info steps
- Visual feedback : writing to target steps that run in multiple copies
- New step categories
- Step filter in step tree tool bar
- Long standing bugs attack
- Long standing wish list attack
- Resource Exporter to export transformations or complete jobs including their used resources (sub-transformations and sub-jobs) to a single ZIP file.
- Named Parameters
- Jobs and transformations can now define parameters with default values that will be available at runtime as variables. This makes it easy to have dynamic configuration of a job/transformation from the command line (e.g. specifying a date range to process with the default being yesterday)
- Dynamic clustering
- Instead of having to configure all of the slaves that a transformation will be executed on in clustered mode, you can run Carte slaves in dynamic mode, configuring them to register with a master (or multiple masters) when they start up. The clustered transformation is configured with a list of the masters it can run on. When the transformation is executed, it will go down the list of masters, attempting to submit the job to each one until it is accepted. That master will then execute the transformation using all of the currently available slaves that are registered to it.
- Hop color scheme with mini-icons, tooltips (note: tooltips not available on OSX currently)
Step changes
New steps
- Analytic Query : get information from previous/first rows
- User Defined Java Expression : evaluate Java expressions, in-line compiled for maximum performance
- Formula step : promoted from a plug-in to a native step
- Synchronize after merge : performs updates, inserts or deletes in a database depending on a flag in the incoming data
- SalesForce Input : reads information from SalesForce (promoted from a plug-in to a native step)
- Replace in string : replace values in strings
- Strings cut : cut strings down to size
- If field value is null : ... then set default values per type or per field
- Mail : send e-mails all over the globe
- Process files: Copy, move or delete files
- Identify last row in a stream : sets a flag when the last row in a stream was reached
- Credit card validator : validates a credit card number, extracts information
- Mail validator : valides an e-mail address
- Reservoir sampling : promoted from a plug-in to a native step
- Univariate statistics : promoted from a plug-in to a native step + upgrade
- LucidDB Bulk loader : high performance bulk loader for the LucidDB column database
- Unique Rows by Hashset : Allows de-duping a stream without having to sort it first. Requires enough memory to be able to store each set of unique keys.
Updated steps
- Table Output: ability to specify the fields to insert
- Calculator : all sorts of new calculations, string manipulations, etc.
- Java script values : ability to replace values + improved script testing
- Database lookup : pre-load cache option (load all values in memory)
- Dimension Lookup/Update:
- Cache pre-load (load all dimension entries in memory)
- Support for alternative start of date range scenarios
- Support for timestamp columns (last update/insert/both)
- Support for current version column
- Combination Lookup/Update : support for last update timestamp column
- Data validator:
- New option to report all errors, not only the first
- Ability to read data from another step
- Group By: added support for cumulative sum and average
- Text File Input: New option to pass through additional fields from previous step (removing the need to do a Cartesian join)
- Mapping:
- Inherit all variables from parent transformation
- Allow setting of variables in mapping
- Allow preview of mapping output
- Improved logging
- New "Open mapping" option in transformation graph right click
Job entry changes
New job entries
- Simple evaluation : Compare a value from previous result or a variable with a given value.
- Evaluate rows number in a table : Check if the number of rows returned by a query resultset is identical, different, greater or smaller than a given value. Can also store those rows in the result for later use.
- Check if connected to the repository : See if there is a live connection
- Export repository to XML file : exports the entire repository to an XML file
Databases
- Boolean support
- Default schema name support
- Support for the InfoBright database
Repository
- Preview repository creation/upgrade SQL before execution
- Schema name support via the database dialog
- Code revision and code hardening
Internationalization
In the i18n department, the overall winners were again the French (Super Samatar Hassan) and Italian (The great Nico Ben) teams. We've had several contributors compliment them for translating keys (or complete steps that got added) in less than a day! The Korean (Kim YoungWoo) and Japanese (Hiroyuki Kawaguch) translators continue to do an excellent catch-up job.
Here is an overview of the translation status:
Language |
% Complete |
|---|---|
en_US |
100,00% |
it_IT |
100,00% |
fr_FR |
100,00% |
ko_KR |
78% |
es_AR |
55% |
ja_JP |
53% |
zh_CN |
49% |
de_DE |
42% |
es_ES |
36% |
nl_NL |
13% |
pt_BR |
11% |
pt_PT |
11% |
Community and codebase
Codebase
Even though we try our best to re-factor and simplify the codebase all the time, there is no denying that the codebase keeps growing.
Right before every release we run the following command:
find . -name "*.java" -exec wc -l {} \; | awk '{ sum+=$1 } END { print sum }'
This is what that gave us over the last releases: 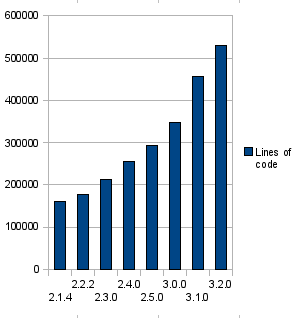
Version |
Lines of code |
Increase |
|---|---|---|
2.1.4 |
160,000 |
|
2.2.2 |
177,450 |
17,450 |
2.3.0 |
213,489 |
36,039 |
2.4.0 |
256,030 |
42,541 |
2.5.0 |
292,241 |
36,211 |
3.0.0 |
348,575 |
56,334 |
3.1.0 |
456,772 |
108,197 |
3.2.0 |
529,277 |
72,505 |
Libraries
As every release since version 3.0, we split off a new library called kettle-db.jar. The total library portfolio of Pentaho Data Integration now includes:
Filename |
Description |
Dependency |
|---|---|---|
kettle-core.jar |
A small set of core classes and utilities for the Kettle environments |
none |
kettle-db.jar |
Contains database related classes |
kettle-core |
kettle-engine.jar |
The transformation and job runtime engines |
kettle-core, kettle-db |
kettle-ui-swtjar |
The UI classes, Spoon, dialogs, etc |
kettle-core, kettle-db, kettle-engine |
Matt Casters - Okegem/Belgium - May 11th 2009