.13 Running a Transformation
- Former user (Deleted)
- Former user (Deleted)
Running a Transformation
- #Running a Transformation Overview
- #Execution Options
- #Setting up Remote and Slave Servers
- #Clustering
Running a Transformation Overview
When you are finished modifying your transformation, you can run it by clicking on the run button from the main menu, toolbar or by pressing F9.
Execution Options
Where to Execute
There are three options for deciding where you want your transformation to be executed:
- Local Execution: the transformation or job will be run on the machine you are currently using
- Execute remotely: allows you to specify a remote server where you want the execution to take place. This feature requires that you have Pentaho Data Integration installed on a remote machine and running the Carte service. See the 14.4.3 Configuring a remote or slave server for more details on setting up remote and slave servers.
- Execute clustered: Allows you to execute the job or transformation in a clustered environment. See the section on Clustering for more details on how to execute a job or transformation in a clustered environment.
Other Options
The following table provides a detailed description of other Execution options:
Option |
Description |
|---|---|
Enable Safe mode |
Places the transformation in Safe Mode. Additional row checking is enabled at runtime, see also: Safe Mode |
Log level |
This allows you to specify the level of detail you want to capture in the log. For detailed descriptions of the log level types see Logging. |
Replay date |
This will set the replay date for when you want to replay the transformation. It will pick up information in the text file input or Excel input steps to skip rows already processed on the replay date. |
Arguments |
This grid allows you to set the value of arguments to be used when running the transformation. |
Variables |
This grid allows you to set the value of variables to be used when running the transformation. |
Setting up Remote and Slave Servers
General description
Slave servers allow you to execute a transformation on a remote server. Setting up a slave server requires having a small web-server running on your remote machine called "Carte" that will accept input from either Spoon (remote & clustered execution) or from the Transformation job entry (clustered execution).
Configuring a remote or slave server
Install Pentaho Data Integration on server you want to use to remotely execute transformations (for more information on setting up a remote server, see the chapter on Installation). The installation includes a small web server called Carte used to support remote requests. Start the Carte server by running Carte.bat (Windows) or carte.sh from the root of your Pentaho Data Integration installation.
Next, you must point your master server to each of the slave server. To do this, double click on 'Slave server' node in the tree control on the left, or by right-clicking on 'Slave Server' and selecting the New Slave Server option.
Service tab options
Option |
Description |
|---|---|
Server name |
The friendly name of the server you wish to use as a slave |
Hostname or IP address |
The address of the machine to be used as a slave |
Port |
Defines the port you wish to use for communicating with the remote server |
Username |
Enter the username credential for accessing the remote server |
Password |
Enter the password credential for accessing the remote server |
Is the master |
This setting tells Pentaho Data Integration that this server will act as the master server in any clustered executions of the transformation |
Note: when executing a transformation in a clustered environment, you should have 1 server setup as the master and all remaining servers in the cluster as slaves.
Proxy tab options
Option |
Description |
|---|---|
Proxy server hostname |
Sets the hostname for the Proxy server you are |
|
connecting through |
The proxy |
Sets the port number used in communication |
server port |
with the proxy |
Ignore proxy for hosts: regexp|separated |
Specify the server(s) for which the proxy should not be active. This option supports specifying multiple servers using regular expressions. You can also add multiple servers and expressions separated by the ' | ' character. |
Clustering
Overview
Clustering allows transformations and transformation steps to be executed in parallel on more than one server. The clustering schema defines which slave servers you want to assign to the cluster and a variety of clustered execution options.
Creating a cluster schema
Begin by double-clicking on the 'Kettle cluster schemas' node in the tree on the left or right-clicking on that node and selecting New clustering schema.
Options
Option |
Description |
|---|---|
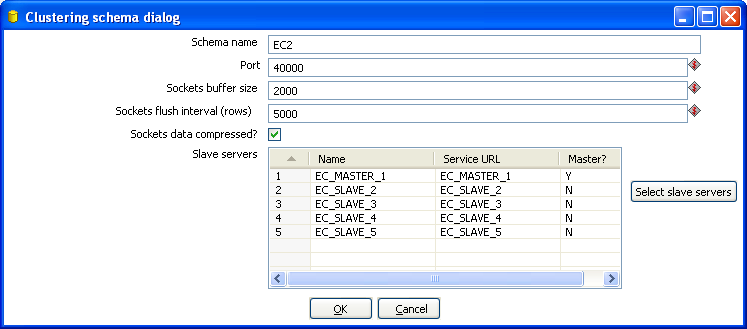
Schema name |
The name of the clustering schema |
Port |
Here you can specify the port from which to start numbering ports for the slave servers. Each additional clustered step executing on a slave server will consume an additional port.
|
Sockets buffer size |
The internal buffer size to use. |
Sockets flush interval |
The amount of rows after which the internal buffer is sent completely over the network and emptied. |
Sockets data compressed? |
When this is checked, all data is compressed using the Gzip compression algorithm to minimize network traffic. |
Slave Servers |
This is a list of the servers to be used in the cluster. You should have one master server and any number of slave servers. To add servers to the cluster, click on the 'Select slave servers' button to select from the list of available slave servers. See ( for more details on how to create a slave server. |
Running transformations using a cluster
When you chose to run a Transformation, select the 'Execute clustered'. You will have the following options:
- Post transformation: Split the transformation and post it to the different master and slave servers.
- Prepare execution: This runs the initialization phase of the transformation on the master and slave servers.
- Start execution: This starts the actual execution of the master and slave transformations.
- Show transformations: Show the generated (converted) transformations that will be executed on the cluster (see the Basic Clustering Example for more information generated transformations).
Basic Clustering Example
Suppose that you have data from a database table and you want to run it through a particularly complex JavaScript program. For performance reasons you want to execute this program on 5 different hosts. You begin by creating a cluster with one master server and 4 slaves:
Then you create the transformation as usual, connecting 2 steps with a hop. You specify that the script to execute is running on a cluster:
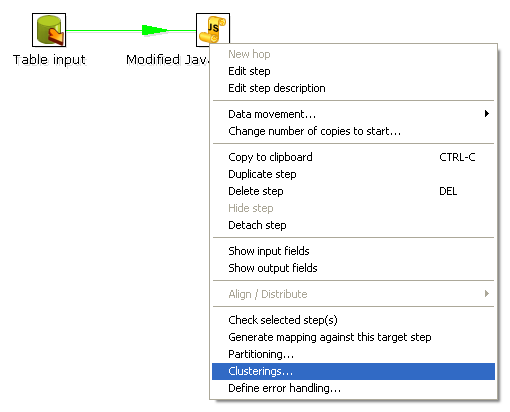
Then select the cluster to use. The transformation will then be drawn like this on the graphical view:

The Cx4 indicates that the step will be executed on a cluster. Suppose we then store the calculated information as a result in a table again:

When we execute this transformation locally, we will see no difference with the usual result you expect from a non-clustered execution. That means that you can use the normal local execution to test the transformation. However when we can execute the transformation in a clustered fashion. In this case, 5 transformations will be generated for the 5 servers in the cluster.
One master:
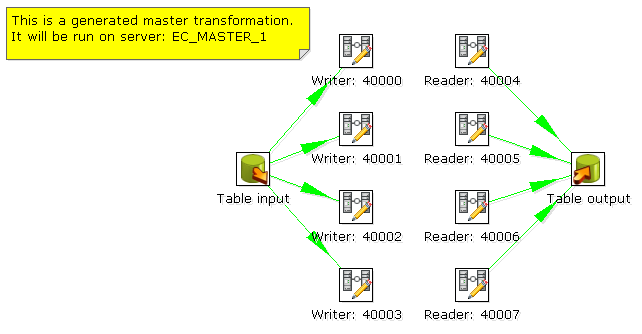
And 4 slaves transformations:
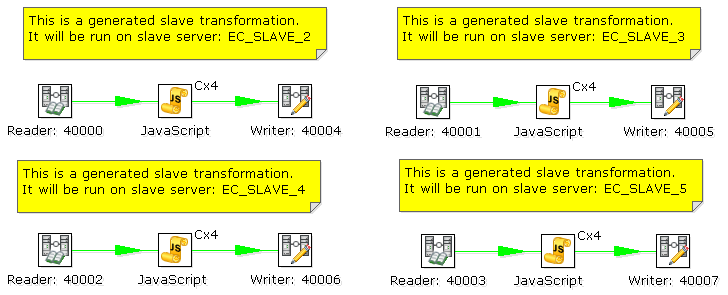
As you can see, data will be sent over the TCP/IP sockets using the Socket Writer and Socket Reader steps.