What's new in PDI version 3.1
- Former user (Deleted)
- Former user (Deleted)
- Former user (Deleted)
- Former user (Deleted)
Index
Introduction
In the period that version 3.1 came about, we had 5 other releases: 2.5.2, 3.0.1, 3.0.2, 3.0.3 and 3.0.4. All the same, we managed to get quite a bit of work done.
The first theme for this release was "Ease of use". It's a theme shared with the rest of the Pentaho platform and tool set. Traditionally, Kettle isn't the worst player in that department, but you can always do better.
The second theme of this release was the complete rework of the documentation set. To keep things manageable by larger groups of people we moved everything we could to the central Pentaho wiki.
Documenting is a difficult task that can never be considered complete but the wiki will help us to keep up with the incredible pace of development that we again achieved in Kettle.
Ease of use
Execution results
To do away with the tab-clutter that came about in the previous release we decided to put the results of executions in a split pane below the graphical view:
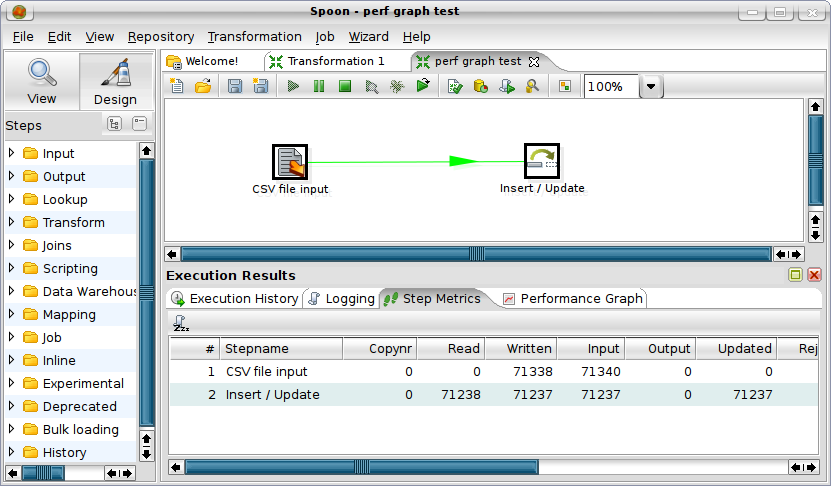
Performance graph
To make it easier to see which step is performing well or not, we periodically (configurable) gather performance statistics and we can show those on a graph:
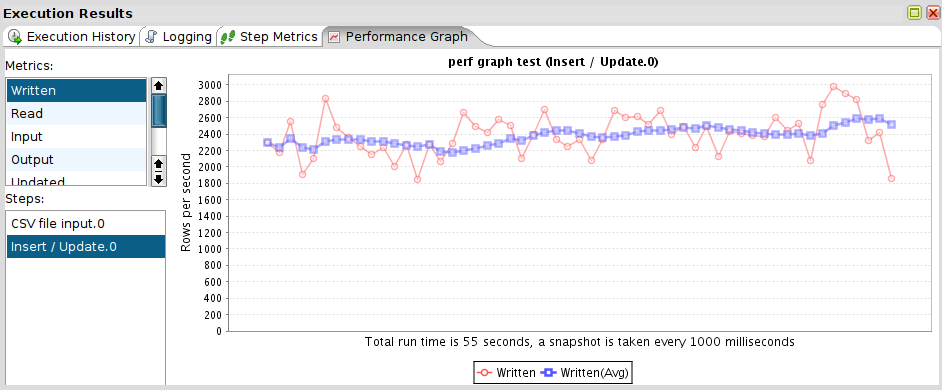
We also allow you to store the raw data behind the graph in a database table so that you can create your own statistics.
FAQ attack
We're constantly on the look out to reduce the size of our FAQ, not increase it. We do this by informing the users of consequences of certain decisions or giving answers to FAQ in the Spoon GUI.
Some of these FAQ attack measures are subtle, like the fact you can now execute a stored procedure without the need for input to go to the step. (it simply executes once).
Others are less subtle, like the tool-tip we show after you dragged the second step onto the canvas:
New database dialog
The old database dialog was sometimes a bit confusing. It became one of the most complete database connection configuration tool, but usability and clarity suffered because of this.
At the same time we had the need for a shared database dialog to be used by different tools in the Pentaho stack. Because of this, we opted to create the dialog in the Mozilla backed XUL standard.
An SWT layer was created and the new dialog is now much easier on the eyes and much easier to use:
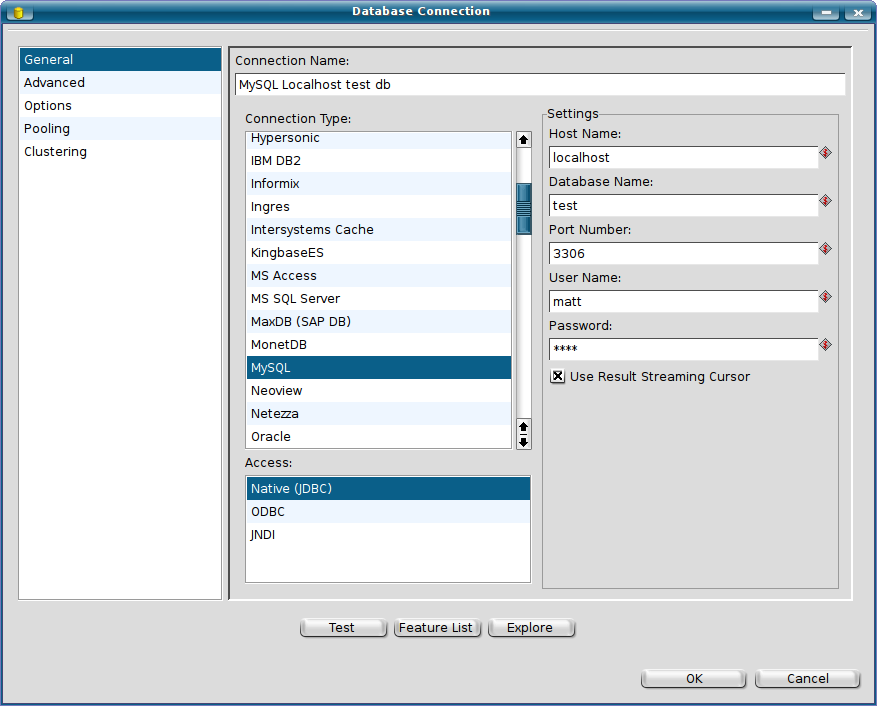
As you can see, only those options that are relevant to the selected database and access type are shown.
Zoom
If you are dealing with large transformations or jobs, it could be useful to zoom in and out of it to keep an overview:
Snap to grid
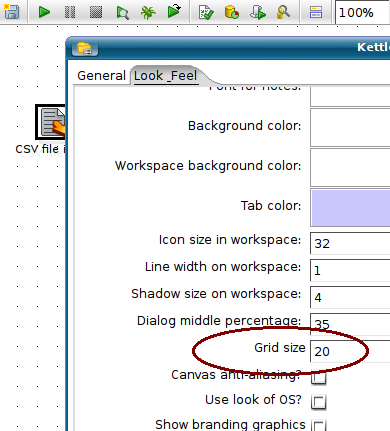
Some people love it, some people hate it, but here it is, the long awaited "snap-to-grid" functionality :
Welcome page / Getting started
We created a "Getting Started" page and linked it on the welcome page. We also linked a number of extra blogs ![]()
Changes in steps
INPUT
- CSV File Input
- Parallel reading
- Multiple files support
- Encoding support
- Fixed File Input
- Multiple files support
- Encoding support
- Property Input
- new step to read properties
- Get data from XML
- New step to parse any type of XML from any source
- Uses XPath
- Generate Random Value
- Handy step in case you want to generate random numbers and strings
- Get Files Rows Count
- get row counts from text files
- LDIF Input
- LDAP Input File support
- Mondrian Input
- Now also supports version 3 of Mondrian
OUTPUT
- Property Output
- Write to a Java properties file
- SQL File Output
- Write data to a file in the form of SQL statements
LOOKUP
- Database Lookup
- cache entire table for better performance
- Web services lookup
- complex data types, etc.
- HTTP client
- Accept URL from an input field
- Check if a column exists
- Verify if a column exists in a database table
- Table Exists
- Verify if a database table exists
- File exists
- Verify if a file exists
TRANSFORM
- Add a checksum
- Calculate a checksum over one or more fields
- Calculator
- Various new calculation types
- Clone row
- Create one or more copies of the passing rows
- Data validator
- Extensive tool to validate your data
- Delay row
- Delay for a certain period before passing each row
- JavaScript
- Support for EMCA v4
- Additional new functions for file handling and much more
- Group By
- Support for cumulative sum and average, stddev, concatenation with specific separator
- Metadata structure
- Document the metadata structure of a stream of data
- Split field to rows
- split a row containing a delimited field into multiple new rows, one per split value.
- Switch / Case
- Split fields into different streams depending on a field value
- XSD Validator
- Validate an XML file/string using a schema
- XSL Transformation
- Transform an XML file/string
SCRIPTING
- Regex Evaluation
- Validate strings using regular expressions
- Grab capture groups and turn them into fields
Joins
- XML Join
- The XML Join Step allows to add xml tags from one stream into a leading XML structure from
a second stream. - Allows you to create complex XML strings
- The XML Join Step allows to add xml tags from one stream into a leading XML structure from
Bulk Loading
Experimental
- Get sub folder names
- Mail validator
- MonetDB bulk loader
- Greenplum bulk loader
- PostgreSQL bulk loader
Job entry changes
The first thing you'll notice is that the job entries are now also split into different categories.
Many job entries have been added in this release and a number got changes too...
File management
- Add filenames to result
- allows you to add a set of files or folders to the result list of the job entry
- Compare folders
- Copy or move result filenames
- Create a folder
- Delete filenames from result
- Delete folders
Conditions
- Check if a folder is empty
- Check if files exist
- Columns exist in a table
Scripting
- Shell
- you can now specify the script to execute in the dialog
File transfer
- SSH2 Get
- SSH2 Put
Repository
- Check if connected to repository
- Export repository to XML file
Databases
Besides the new database dialog (see above) we also added support for a few new database types. We now have support for 34 database types and a generic database connection for the others.
Here are the new ones...
- MonetDB : the Dutch open source column database
- KingbaseES : the popular Chinese RDBMS (PostgreSQL based)
- Vertica : The upcoming high performance column database
- HP NeoView : HP's answer to operational BI
Internationalization
In the i18n department, all teams made great strides but we would like to especially thank the Korean (Kim YoungWoo) and Japanese (Hiroyuki Kawaguch) translators for an excellent job.
Here is an overview of the translation status:
Language |
% Complete |
Keys done (shown in the language) |
Keys missing (shown in English) |
|---|---|---|---|
en_US |
100,00% |
9442 |
0 |
it_IT |
100,00% |
9442 |
0 |
fr_FR |
100,00% |
9442 |
0 |
es_AR |
64 |
6069 |
3373 |
ko_KR |
61 |
5740 |
3702 |
ja_JP |
57 |
5341 |
4101 |
zh_CN |
53 |
5021 |
4421 |
de_DE |
48 |
4539 |
4903 |
es_ES |
41 |
3853 |
5589 |
nl_NL |
15 |
1432 |
8010 |
pt_BR |
13 |
1237 |
8205 |
pt_PT |
13 |
1236 |
8206 |
Also many kudos to the Italian (The great Nico Ben) and French (Super Samatar Hassan) translators for keeping up there at 100%. Given the ever so fast development pace, this is no small feat!!
Community and codebase
A word of thanks
As in any good open source project, our community was the driving force behind this excellent release. Pentaho obviously spent a large amount of time on this release but it wouldn't have been the same without the valuable help of all our developers, testers, bug reporters, partners, customers, documenters, translators, forum members, etc. It would lead us too far to thank everyone but it's all of you that keep Kettle going!
Even though all contributions are valued a lot, I would like to give special thanks to Samatar Hassan, Daniel Einspanjer (at Mozilla) and Ingo Klose (at SHS-Viveon) for their contributions to this release.
On the Pentaho team I would like to applaud Jem for porting that pesky Spoon users guide over to the Wiki. Many thanks to the whole team for all the help!
Codebase
Even though we try our best to re-factor and simplify the codebase all the time, there is no denying that the codebase keeps growing.
Right before every release we run the following command:
find . -name "*.java" -exec wc -l {} \; | awk '{ sum+=$1 } END { print sum }'
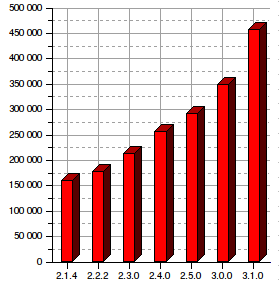
This is what that gave us over the last releases:
Version |
Lines of code |
Increase |
|---|---|---|
2.1.4 |
160,000 |
|
2.2.2 |
177,450 |
17,450 |
2.3.0 |
213,489 |
36,039 |
2.4.0 |
256,030 |
42,541 |
2.5.0 |
292,241 |
36,211 |
3.0.0 |
348,575 |
56,334 |
3.1.0 |
456,772 |
108,197 |
As you can see, there is no sign of any slowdown in the development of the Kettle codebase. Looking at the roadmap this is bound to stay like that for the foreseeable future.
Matt Casters - Okegem/Belgium - September 18th 2008