Pentaho MapReduce
- Former user (Deleted)
- Virginia Agnew
- Matt Tucker
![]() PLEASE NOTE: This documentation applies to an earlier version. For the most recent documentation, visit the Pentaho Enterprise Edition documentation site.
PLEASE NOTE: This documentation applies to an earlier version. For the most recent documentation, visit the Pentaho Enterprise Edition documentation site.
Pentaho MapReduce
Note: This entry was formerly known as Hadoop Transformation Job Executor.
This job entry executes transformations as part of a Hadoop MapReduce job. This is frequently used to execute transformations that act as mappers and reducers in lieu of a traditional Hadoop Java class. The User Defined tab is for Hadoop option name/value pairs that are not defined in the Job Setup and Cluster tabs. Any properties defined here will be set in the MapReduce job configuration.
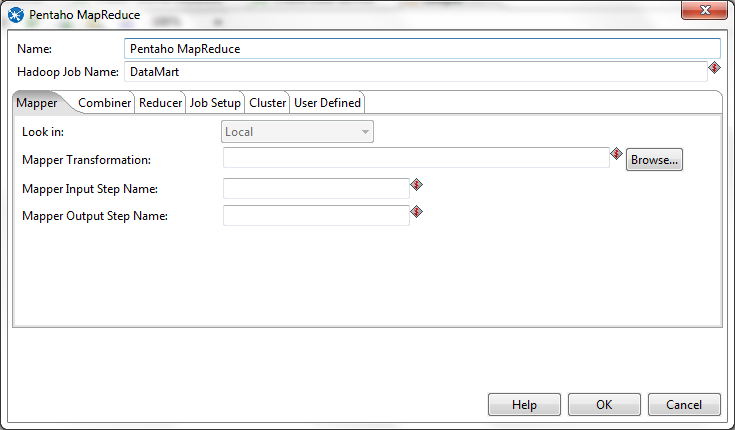
General
Option | Definition |
|---|---|
Name | The name of this Pentaho MapReduce entry instance |
Hadoop Job Name | The name of the Hadoop job you are executing |
Mapper
Option | Definition |
|---|---|
Look in | Sets the context for the Browse button. Options are: Local (the local filesystem), Repository by Name (a PDI database or solution repository), or Repository by Reference (a link to a transformation no matter which repository it is in). |
Mapper Transformation | The KTR that will perform the mapping functions for this job. |
Mapper Input Step Name | The name of the step that receives mapping data from Hadoop. This must be a MapReduce Input step. |
Mapper Output Step Name | The name of the step that passes mapping output back to Hadoop. This must be a MapReduce Output step. |
Combiner
Option | Definition |
|---|---|
Look in | Sets the context for the Browse button. Options are: Local (the local filesystem), Repository by Name (a PDI database or solution repository), or Repository by Reference (a link to a transformation no matter which repository it is in). |
Combiner Transformation | The KTR that will perform the combiner functions for this job. |
Combiner Input Step Name | The name of the step that receives combiner data from Hadoop. This must be a MapReduce Input step. |
Combiner Output Step Name | The name of the step that passes combiner output back to Hadoop. This must be a MapReduce Output step. |
Combine single threaded | Indicates if the Single Threaded transformation execution engine should be used to execute the combiner transformation. If false, the normal multi-threaded transformation engine will be used. The Single Threaded transformation execution engine reduces overhead when processing many small groups of output. |
Reducer
Option | Definition |
|---|---|
Look in | Sets the context for the Browse button. Options are: Local (the local filesystem), Repository by Name (a PDI database or solution repository), or Repository by Reference (a link to a transformation no matter which repository it is in). |
Reducer Transformation | The KTR that will perform the reducer functions for this job. |
Reducer Input Step Name | The name of the step that receives reducing data from Hadoop. This must be a MapReduce Input step. |
Reducer Output Step Name | The name of the step that passes reducing output back to Hadoop. This must be a MapReduce Output step. |
Reduce single threaded | Indicates if the Single Threaded transformation execution engine should be used to execute the reducer transformation. If false, the normal multi-threaded transformation engine will be used. The Single Threaded transformation execution engine reduces overhead when processing many small groups of output. |
Job Setup
Option | Definition |
|---|---|
Suppress Output of Map Key | If selected the key output from the Mapper transformation will be ignored and replaced with NullWritable. |
Suppress Output of Map Value | If selected the value output from the Mapper transformation will be ignored and replaced with NullWritable. |
Suppress Output of Reduce Key | If selected the key output from the Combiner and/or Reducer transformations will be ignored and replaced with NullWritable. This requires a Reducer transformation to be used, not the "Identity Reducer". |
Suppress Output of Reduce Value | If selected the key output from the Combiner and/or Reducer transformations will be ignored and replaced with NullWritable. This requires a Reducer transformation to be used, not the "Identity Reducer". |
Input Path | A comma-separated list of input directories , such as /wordcount/input, from your Hadoop cluster where the source data for the MapReduce job is stored. |
Output Path | The directory on your Hadoop cluster where you want the output from the MapReduce job to be stored., such as //wordcount/output. The output directory cannot exist prior to running the MapReduce job. |
Input Format | The Apache Hadoop class name that describes the input specification for the MapReduce job. See InputFormat for more information. |
Output Format | The Apache Hadoop class name that describes the output specification for the MapReduce job. See OutputFormat for more information. |
Clean output path before execution | If enabled the output path specified will be removed before the MapReduce job is scheduled. |
Cluster
Option | Definition |
|---|---|
Hadoop Cluster | Allows you to create, edit, and select a Hadoop cluster configuration for use. The Hadoop Cluster section below defines the options for editing or creating an entry for this option. The Edit button allows you to edit Hadoop cluster configuration information. The New button allows you to add a new Hadoop cluster configuration. Information on Hadoop Clusters can be found in Pentaho Help. |
Number of Mapper Tasks | The number of mapper tasks you want to assign to this job. The size of the inputs should determine the number of mapper tasks. Typically there should be between 10-100 maps per node, though you can specify a higher number for mapper tasks that are not CPU-intensive. |
Number of Reducer Tasks | The number of reducer tasks you want to assign to this job. Lower numbers mean that the reduce operations can launch immediately and start transferring map outputs as the maps finish. The higher the number, the quicker the nodes will finish their first round of reduces and launch a second round. Increasing the number of reduce operations increases the Hadoop framework overhead, but improves load balancing. If this is set to 0, then no reduce operation is performed, and the output of the mapper becomes the output of the entire job; also, combiner operations will also not be performed. |
Enable Blocking | Forces the job to wait until each step completes before continuing to the next step. This is the only way for PDI to be aware of a Hadoop job's status. If left unchecked, the Hadoop job is blindly executed, and PDI moves on to the next job entry. Error handling/routing will not work unless this option is checked. |
Logging Interval | Number of seconds between log messages. |
Hadoop Cluster
The Hadoop cluster configuration dialog allows you to specify configuration detail such as host names and ports for HDFS, Job Tracker, and other big data cluster components, which can be reused in transformation steps and job entries that support this feature.
Option | Definition |
|---|---|
Cluster Name | Name that you assign the cluster configuration. |
Use MapR Client | Indicates that this configuration is for a MapR cluster. If this box is checked, the fields in the HDFS and JobTracker sections are disabled because those parameters are not needed to configure MapR. |
Hostname (in HDFS section) | Hostname for the HDFS node in your Hadoop cluster. |
Port (in HDFS section) | Port for the HDFS node in your Hadoop cluster. |
Username (in HDFS section) | Username for the HDFS node. |
Password (in HDFS section) | Password for the HDFS node. |
Hostname (in JobTracker section) | Hostname for the JobTracker node in your Hadoop cluster. If you have a separate job tracker node, type in the hostname here. Otherwise use the HDFS hostname. |
Port (in JobTracker section) | Port for the JobTracker in your Hadoop cluster. Job tracker port number; this cannot be the same as the HDFS port number. |
Hostname (in ZooKeeper section) | Hostname for the Zookeeper node in your Hadoop cluster. |
Port (in Zookeeper section) | Port for the Zookeeper node in your Hadoop cluster. |
URL (in Oozie section) | Field to enter an Oozie URL. This must be a valid Oozie location. |
User Defined
Option | Definition |
|---|---|
Name | Name of the user defined parameter or variable that you want to set. To set a java system variable, preface the variable name with java.system, like this: java.system.SAMPLE_VARIABLE. Kettle variables that are set here override the Kettle variables set in the kettle.properties file. For more information on how to set a kettle variable, see the Set Kettle Variables help topic in the Pentaho Help documentation. |
Value | Value of the user defined parameter or variable that you want to set. |