Migrating JavaScript from 2.5.x to 3.0.0
- Former user (Deleted)
- Former user (Deleted)
- Former user (Deleted)
- Former user (Deleted)
Introduction
Because the Pentaho Data Integration JavaScript steps can contain just about anything and because the old way of doing anything outside of the ordinary will not work anymore, we will offer alternative ways of reaching your goals in this document.
The core of the problem is that a number of special operations that where executed in JavaScript required the Kettle Java API. This API has changed dramatically in version 3.0.
Modifying values
In the past we allowed values to be modified on the spot. Methods for doing so include:
- setValue()
- str2dat()
- dat2str()
- str2num()
- num2str();
- ...
We still allow the use of these methods in compatibility mode. However, the result stored in the modified value will be modified to the expected data type.
This data conversion is silent as it uses the v2 data conversion engine.
We force these conversions because in the past the conflicting data types have caused a lot of problems in transformations. Having alternating data types in a field in a row is not a good situation to have.
That is because it causes problems during serialization of rows (Sort Rows, Clustered execution, Serialize to file, ...) and during database manipulations (Table Output, Database Lookup, Database Join, Update, etc)
The problems
For example, let us take a look at the data conversion excersice:
dateField.dat2str("dd-MM-yyyy")
The data type of field "dateField" is Date. The data is internally being converted to String. As such, the data type conflicts with the expected "Date" type
Because of that, before the value is sent to the next steps, the data type is changed back to Date from String. This uses the default mask ("yyyy/MM/dd HH:mm:ss.SSS") and as such, the conversion will fail.
The net result is that the dateField will contain value null.
Another, more subtle, example of data type conflicts comes from the fact that the JavaScript engine doesn't always use the data type you expect. For example, take a look at this simple statement:
integerField.setValue(5);
You would think that the data type in v2 would be an integer, when in fact the JavaScript engine uses floating point values all over the place.
That means that the Integer integerField magically switched to a Number data type in version 2. That in itself sometimes caused problems in various areas.
In version 3, the data type will be converted back to Integer. Even so, there can be plenty of situations where you would end up with a data conversion problem.
The solution
The solution is always to make sure that you create new values when doing data type conversions. Another piece of advice (as shown below) is to stop using the compatibility mode.
As such, the statements above becomes:
var stringField = date2str(dateField, "dd-MM-yyyy");
or
var integerResult = 5;
Compatibility mode
By default old JavaScript programs will run in compatibility mode. That means that the step will try to act as much like the old step as possible.
In turn this mean you might see a small performance drop because of all the extra work this step needs to do.
If you want to make as much use as possible of the new architecture, you can turn this mode off and change the code as such:
- intField.getInteger() --> intField
- numberField.getNumber() --> numberField
- dateField.getDate() --> dateField
- bigNumberField.getBigNumber() --> bigNumberField
- etc.
In stead of using the various Java methods you can use the built-in library. You will also note that the resulting program code is more intuitive to use.
For example :
- checking for null is now: field.isNull() --> field==null
- Converting string to date: field.Clone().str2dat() --> str2date(field)
- etc.
If you convert your code like this, you might enjoy significant performance benefits.
Please note that it is no longer possible to modify data in-place using the value methods. This was a design decision to make sure that no data with the wrong type ends up in the output rows of the step.
This was a possibility in version 2 and caused some problems in transformations here and there in the steps after the JavaScript steps. Instead of modifying fields in-place, create new fields using the table at the bottom of the Modified Javascript transformation. Then assign values to them directly in the script, as if they were variables.
Java code & be.ibridge.kettle packages
Since the complete core API of Pentaho Data Integration changed it is no longer possible to use the be.ibridge.kettle packages in in-line Java in your JavaScript code.
There are 2 paths to a solution for this problem.
Helper methods
The best way to stay portable towards the future is obviously to stop using the internal PDI Java packages in your source code.
As you can see in the chapter below "Adding rows dynamically" we have been exposing new methods to the JavaScript engine to help you out.
For example:
- Packages.be.ibridge.kettle.core.util.StringUtil.getVariable --> getVariable()
- Packages.be.ibridge.kettle.core.util.StringUtil.setVariable --> setVariable()
Move to org.pentaho.di packages
Obviously it is still possible (though not recommended) to use the internal PDI API. Most of the time the methods have stayed the same but simply moved to the org.pentaho.di naming of packages.
For example:
var cr = Packages.be.ibridge.kettle.core.Const.CR;
Changes to
var cr = Packages.org.pentaho.di.core.Const.CR;
Base64 encoding and decoding of strings
Even though the Apache Commons Base64 encoding and decoding library was available before, the Base64 sample in version 2 used an be.ibridge class to do the work.
In version 3 we suggest you use the excellent Apache Commons library as shown in the updated sample:
var bytes = Packages.org.apache.commons.codec.binary.Base64.decodeBase64( F1.getString().getBytes() ); var decString = new Packages.java.lang.String( bytes ); var encString = new Packages.java.lang.String( Packages.org.apache.commons.codec.binary.Base64.encodeBase64( decString.getBytes() ) );
Adding rows dynamically
In the samples you'll find a transformation called "JavaScript - create new rows.ktr" that creates new rows based on the content of a field.
In the example, this is the input for the JavaScript step: 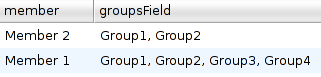
For each of the values in the column "groupsField" we want to generate a new row. Here's how it was in the old version:
var groups = group.getString().split(",");
for (i=0;i<groups.length;i++)
{
newRow = row.Clone();
newRow.addValue( new Packages.be.ibridge.kettle.core.value.Value("subgroup", groups[i]).trim() );
newRow.addValue( new Packages.be.ibridge.kettle.core.value.Value("ignore", "N").trim() );
_step_.putRow(newRow);
}
var subgroup = "";
var ignore = "Y";
In version 3.0 we have split up data and metadata. We also added a number of methods to the JavaScript engine to help ease the pain in this regard:
if (groupsField!=null)
{
var groups = groupsField.split(",");
for (i=0;i<groups.length;i++)
{
newRow = createRowCopy(getOutputRowMeta().size());
var rowIndex = getInputRowMeta().size();
newRow[rowIndex++] = trim( groups[i] );
newRow[rowIndex++] = "N";
putRow(newRow);
}
}
var subgroup = "";
var ignore = "Y";
As you can see, we added a few methods:
method |
explanation |
|---|---|
getInputRowMeta() |
The metadata of the input row, explaining the layout of the row data and the "row" object. |
getOutputRowMeta() |
The metadata of the output row, determined by the input metadata and the extra fields specified in this step. (Fields section) |
createRowCopy(size) |
Create a copy of the input row data, but re-size the resulting row to the desired length. |
putRow(row) |
Write a new row to the next steps in the transformation. The data type passed is Object[]. The data types passed MUST match those specified in the Fields section and as such the specification in getOutputRowMeta(). It is not legal to specify a String for a field and to pass a different data type.
|
The result of the script is in both versions the following: 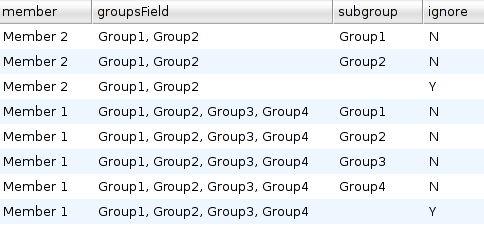
A simple filter on the "ignore" field gives the desired result.
We believe that the new API will better stand the test of time because it is written without use of a direct Java code or the Java API.