Mappings in Kettle
- Former user (Deleted)
- Former user (Deleted)
- Former user (Deleted)
May 9, 2006
Submitted by Matt Castors, Chief of Data Integration, Pentaho
The fourth Kettle Weekly Tip took a while longer to create because my development system (laptop) has been traveling back and forth to Acer support for the last 3 weeks. I have a 3 year support contract with total accident coverage on this very nice machine, but I guess sometimes you just run out of luck.
In case any of you wonder, all screenshots were taken on SuSE Linux 10.1RC3, running Gnome version 2.12.2. running XGL.
IMPORTANT: make sure you use Kettle release 2.3.0 or later because a lot of bugs in Mappings have been fixed the last couple of weeks. Thank you for your understanding!
What is a mapping?
A mapping is the Kettle solution for transformation re-use.
For example if you have a complex calculation that you want to re-use everywhere, you can use a mapping.
A mapping is also called a sub-transformation because it is a transformation just like any other with a couple of key differences:
Every mapping needs a Mapping Input step to define the fields that are required for the mapping to work correctly.
Every mapping needs a Mapping Output step to define the fields that are generated by the mapping.
Because of the static nature of a mapping, Previewing mapping makes no sense.
An example mapping
This is an example mapping that calculates turnover and profit based on 4 input fields:
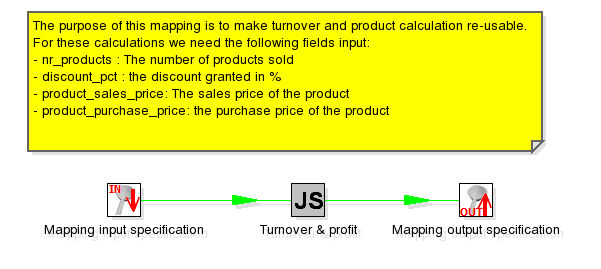
The Mapping Input
Because we define only a small piece of a larger transaction, we need to know which fields are used as input for the mapping.
To handle this, we use a step called a Mapping Input Specification:
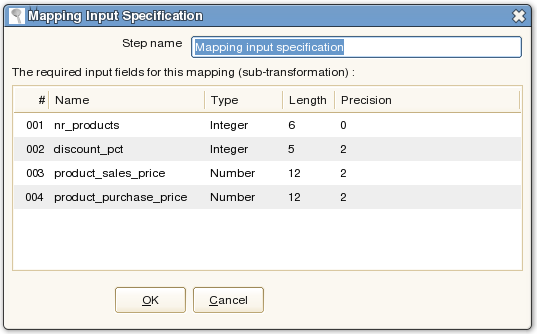
Once we specified the input, the next steps in the transformation know what to expect. It's also logical that we can have ONLY ONE mapping input step in a mapping.
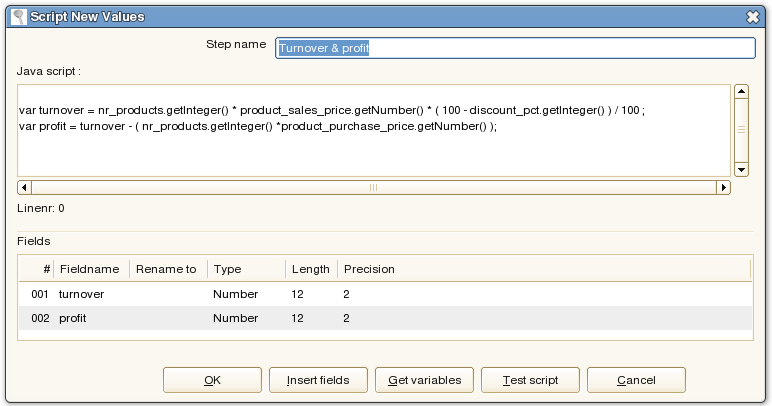
The Mapping Body
When we know the input we can all steps in a transformation to build logic with it. In this example we'll be calculating turnover and profit:
The Mapping Output
At the end of the transformation, we need to have one exit point for the transformation: this is the point were the rows of data are given back to the parent transformation that calls this mapping.
We do this by using ONLY ONE mapping output specification step:
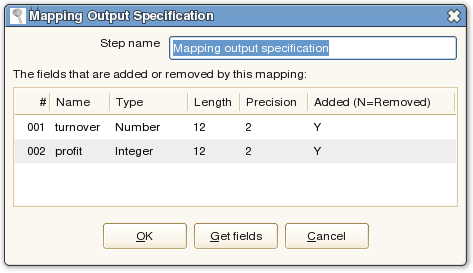
So what we're saying is: specify the fields that are added to the stream by the mapping you just defined. In our case that would be turnover and profit.
In case fields are removed, you need to specify these as well.
Doing this helps the parent transformation in determining the meta-data changes in the row.
The Mapping Example
OK, so now that the mapping was created, how do we use it?
Well, simply by using the mapping step as shown in the image below. (click to enlarge)
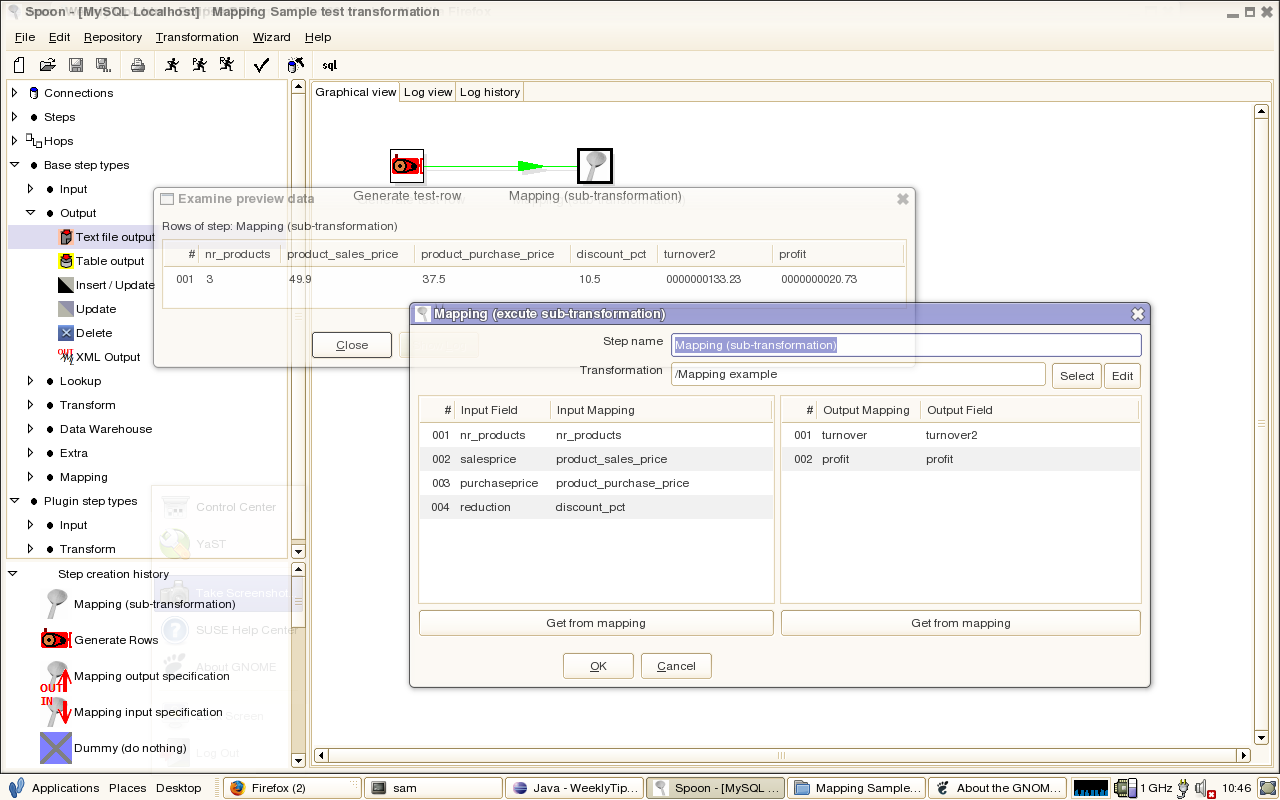
In our case it's driven by a single row of data, but I'm sure each of you can find more exciting examples.
I hope you found this Weekly Kettle Tip interesting. Join us next week for more Kettle fun.
Matt