Avro Output
![]() PLEASE NOTE: This documentation applies to an earlier version. For the most recent documentation, visit the Pentaho Enterprise Edition documentation site.
PLEASE NOTE: This documentation applies to an earlier version. For the most recent documentation, visit the Pentaho Enterprise Edition documentation site.
Description
The Avro output step serializes data into Avro binary or JSON format, then writes to file on disk.
This output step creates 2 files: 1) the file containing output data in Avro format and 2) an Avro schema file - defined by the output step "fields"
Fields can be defined manually or extracted from incoming steps.
Options
Main Configuration
Option | Definition | Example | ||
|---|---|---|---|---|
Step name | The name of this step as it appears in the transformation workspace. | |||
Location | File system type of where the Avro output data will be written | Local, Hadoop Cluster, S3, HDFS, MapRFS | ||
File name | The fully qualified URL where the Avro output data will be written. URL will be of different format depending on file system type (Location field). |
Fields Tab
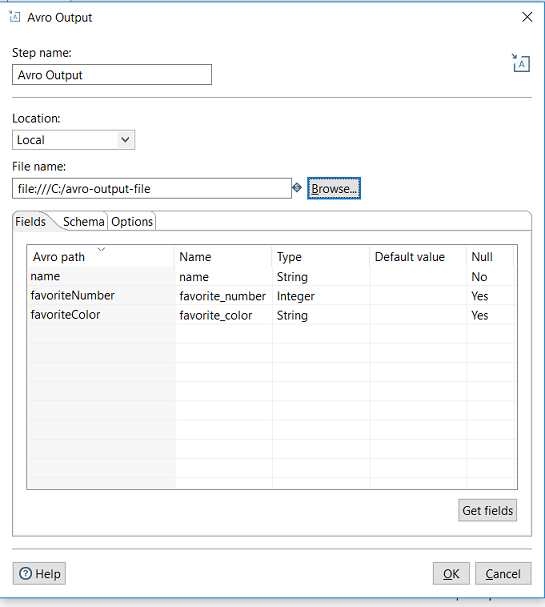
The Fields tab defines the fields that will make up the Avro schema that will be created by this step. These fields can be defined manually. Or users can click "Get Fields" button to populate these fields from the incoming PDI stream.
Option | Definition | Example(s) |
|---|---|---|
Avro path | The name of the field as it will appear in the Avro Schema and avro file | |
Name | The name of the PDI field | |
Type | The data type of the field | String, Integer, etc |
Default value | The default value of the field if it is null or empty | |
Null | Is this field allowed to have null values? | Yes, No |
Get Fields (button) | If user clicks this button, the fields table will be populated with fields from the incoming PDI stream |
Note
If the "Null" field is set to "No", null values are not allowed for this field. If the incoming data contain null values for such fields, the transformation will fail. To avoid this, make sure the "Default value" field is populated for all fields where "Null" is set to "No".
Schema Tab
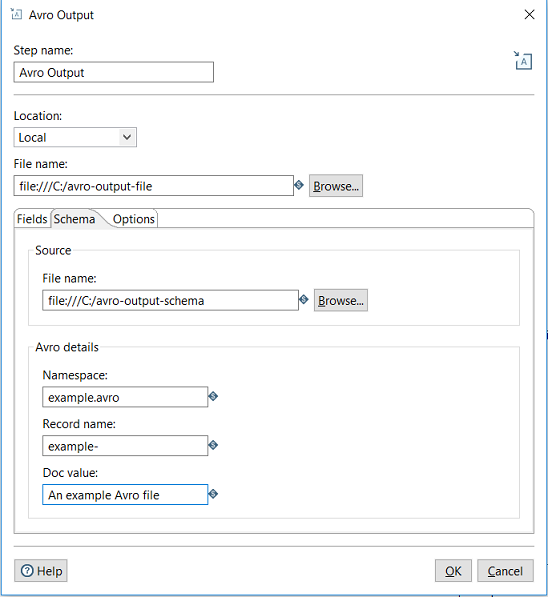
The schema tab defines options for how the Avro schema file will be created. Reference: https://avro.apache.org/docs/1.8.1/spec.html#schema_record
Option | Definition | Example(s) |
|---|---|---|
File Name | The fully qualified URL where the Avro schema file will be written. URL will be of different format depending on file system type (Location field). If a schema file already exists, it will be overwritten. Otherwise, a new file will be created. | |
Namespace | Together with the "Record name" field, this defines the "full name" of the schema (example.avro.User in this case). | example.avro |
Record name | The name of the Avro record | User |
Doc value | provides documentation to the user of this schema |
Options Tab
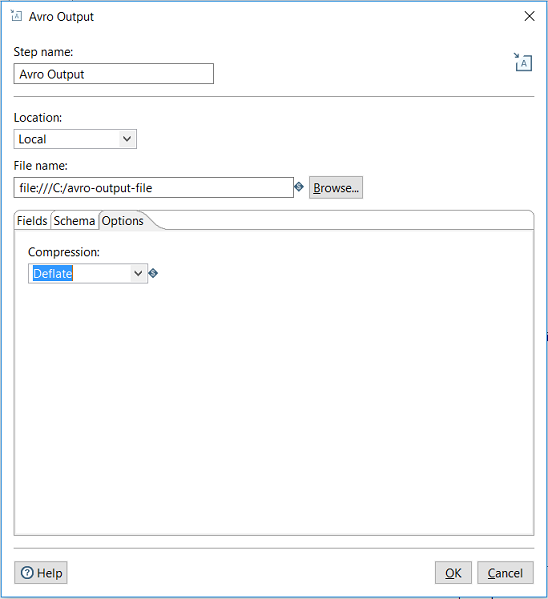
The options tab contains additional options you can define for Avro output file / schema. In this case, there is only 1: compression. Reference: https://avro.apache.org/docs/1.8.1/spec.html#Object+Container+Files
Options | Definition | Example(s) |
|---|---|---|
Compression | the name of the compression codec used to compress blocks in Avro output file | None, Deflate, Snappy |
Metadata Injection Support (7.x and later)
All fields of this step support metadata injection. You can use this step with ETL Metadata Injection to pass metadata to your transformation at runtime.