Using the Weka Scoring Plugin
- Former user (Deleted)
- Former user (Deleted)
Contents
1 Introduction
The Weka scoring plugin is a tool that allows classification and clustering models created with Weka to be used to "score" new data as part of a Kettle transform. "Scoring" simply means attaching a prediction to an incoming row of data. The Weka scoring plugin can handle all types of classifiers and clusterers that can be constructed in Weka. As of Weka version 3.6.0, it can also handle certain types of models expressed in the Predictive Modeling Markup Language (PMML). The Weka scoring plugin provides the ability to attach a predicted label (classification/clustering), number (regression) or probability distribution (classification/clustering) to a row of data.
Note
Only certain classifiers and clusterers are capable of producing probability estimates.
2 Getting Started
In order to use the Weka scoring plugin, a model must first be created in Weka and then exported as a serialized Java object to a file. Alternatively, an existing supported PMML model can be used. The model can then be loaded by the plugin and applied to fresh data. This section briefly describes how to create and export a model from Weka.
2.1 Starting the Weka Explorer
Assuming you have Weka 3.6.x or 3.7.x installed, launch the Weka environment by double-clicking on the weka.jar file or by selecting it from the Start menu (under Windows). Once the UI is visible, click the Explorer button. 
Alternatively, you can start the Explorer directly from the command line by typing:
java -cp path_to_directory_containing_weka/weka.jar weka.gui.explorer.Explorer
The latter approach allows you to control how much memory is made available to the Java virtual machine through the use of the "-Xmx" flag.
Note
Within PDI 5.3, we ship the Weka 3.7.11 core jar file in the Weka plugins in PDI. Models created in Weka 3.6.x are not compatible. You'll need to download and install Weka 3.7.11, recreate the model, and then load it into the Weka scoring step.
2.2 Loading Data into the Explorer
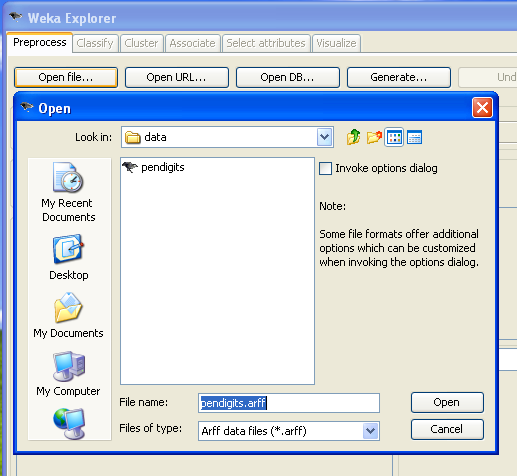
Data can be imported into the explorer from files (arff, csv or c4.5 format) or from databases. In this example we will load data from a file in Weka's native arff (Attribute Relation File Format) format. Click on "Open File" and select the "pendigits.arff" file (this file is located in the docs/data directory in the Weka Scoring plugin archive). The file will be loaded and summary statistics for the attributes shown in the Preprocess panel.
2.3 Building a Classifier
In the Classifier panel of the Explorer first choose a learning scheme to apply to the training data. In this example you will use a decision tree learner (J48).
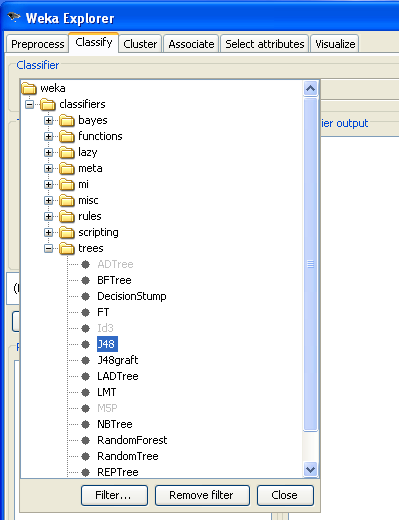
Clicking on the scheme summary will bring up a dialog window that allows you to configure the parameters of J48. The defaults work well in most cases. The rest of the default settings for evaluation are good for most situations, so you can simply press the "Start" button to launch the training and evaluation of the learning scheme. The default is to perform a 10-fold cross-validation of the learning scheme on the training data, so the statistics on performance that are reported are fairly reliable estimates of what can be expected on future data.
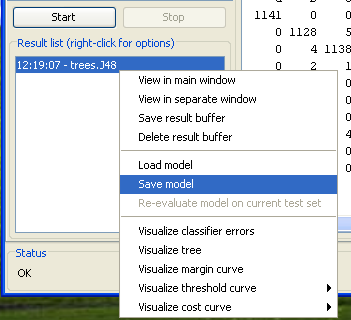
2.4 Exporting the Trained Classifier
You can save export any classifier that you have trained in the Classifier panel by right clicking on its entry in the Results History. Trained models are stored on disk a serialized Java objects. Save this model to a file called "J48" (a ".model" extension will be added for you).
3 Using the Weka Classifier in Kettle
Using the trained model in Kettle to score new data is simply a matter of configuring the Weka scoring plugin to load and apply the model file you created in the previous section.
A Simple Example
As a simple demonstration of how to use the scoring plugin, you will use the model you created in Weka to score the same data that it was trained on. First start Spoon, and then construct a simple transform that links a CSV input step to the Weka scoring step.
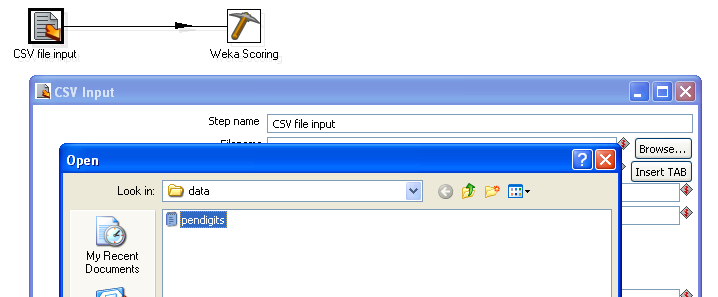
Next, configure the CSV input step to load the "pendigits.csv" file (this is the same data as pendigits.arff, but in csv format). Make sure that the Delimeter text box contains a "," and then click on "Get Fields" to make the CSV input step analyze a few lines of the file and determine the types of the fields.
Now configure the Weka scoring step. First load your J48 model.
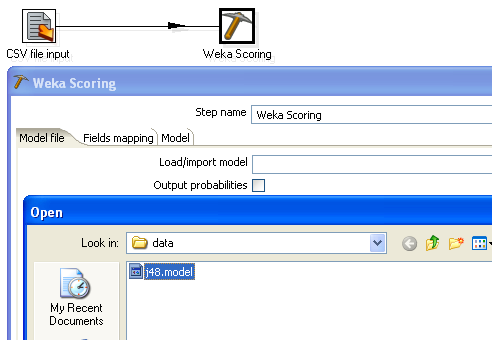
The fields mapping tab of the scoring dialog shows how the fields in the incoming data from the previous step in the transform - the CSV input step - have been matched with the attributes in the data that the model was trained from. Any attributes that don't have a counterpart in the incoming data are indicated by an entry labeled "missing". If there is a difference in type between a model attribute and an incoming field, then this will be indicated by the label "type-mismatch". In both cases, the classifier will receive missing value as input for the attribute in question for all incoming data rows. In the figure below, there is a type mismatch between the attribute "class" and the incoming field with the same name.
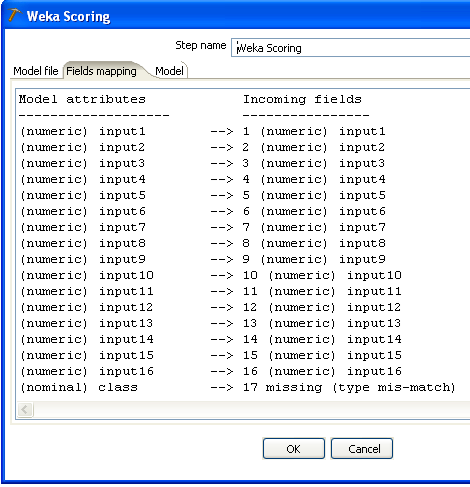
Returning to the CSV input step's configuration dialog, it can be seen that the type of the "class" field has been identified as "Integer". While this is correct as far as the raw data goes, this attribute has been encoded as nominal in the arff file that the classifier was trained from. You can resolve this type mismatch by changing the type of this field to "String" in the CVS input step's dialog. 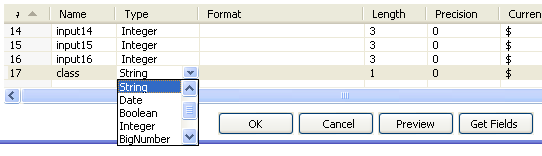
Note
For the purposes of scoring data it is not necessary to rectify this type mismatch. In fact, the target or class column can be missing entirely.
The "Model" tab of the Weka scoring step's dialog shows the textual description of the classifier (exactly as it was shown in the Classifier panel of the Weka Explorer). 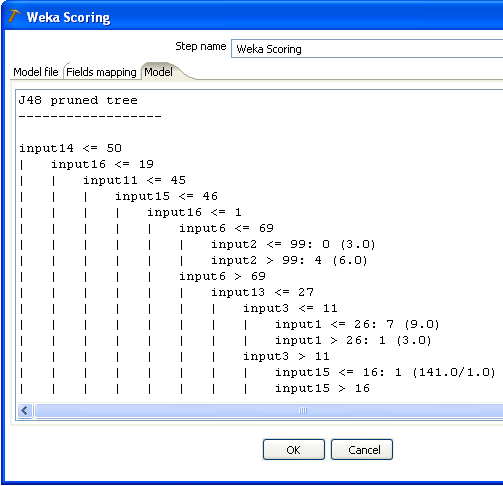
Click on the "Preview" button in Spoon to preview the result of using the classifier to score the pendigits data. Predictions for the "class" field have been appended as a new field at the end of the data.
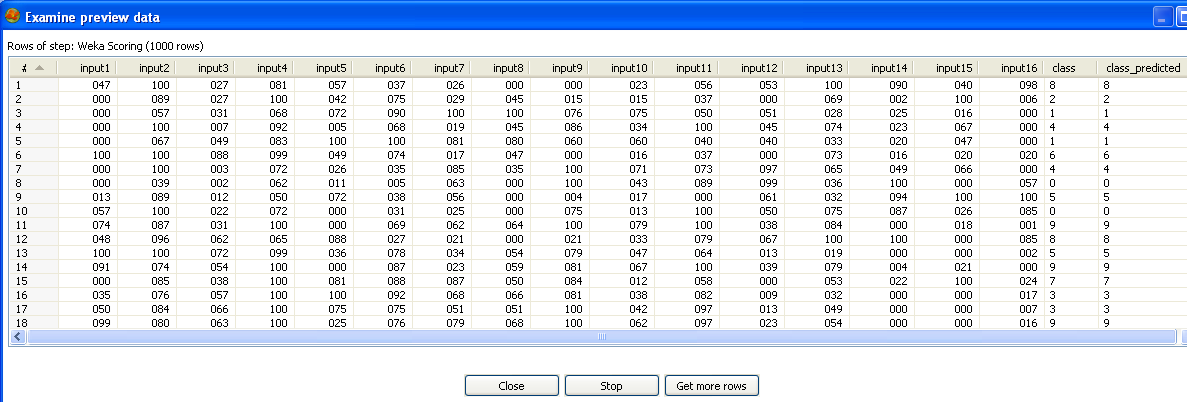
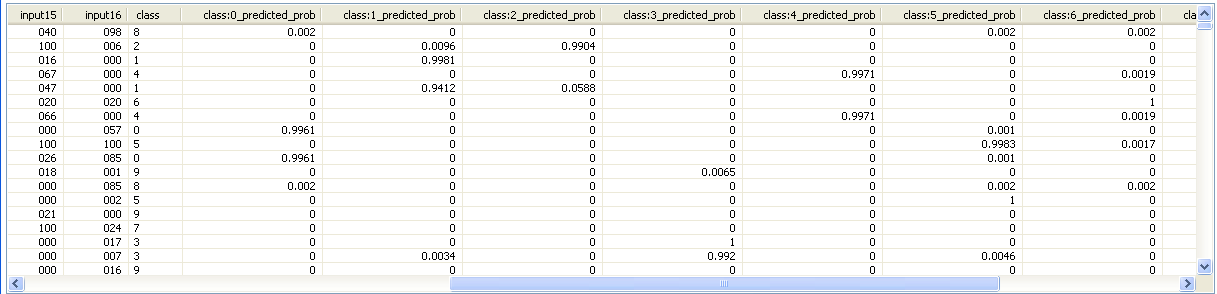
Enabling the "Output probabilities" checkbox on the Weka scoring dialog's "Model file" tab will result in a predicted probability distribution being appended to each incoming data row. In this case there will be one new field containing a predicted probability for each possible class label (Note: this option is only available for models that have been trained on a discrete class problem).
4 Advanced Features
4.1 Storing Models in Kettle XML Configuration File or Repository
When a transform is executed, the Weka scoring plugin will load the model from disk using the path specified in the File tab. It is also possible to store the model in Kettle's XML configuration file or the repository and use this instead when the transform is executed. To do this, first load a model into the Weka scoring step as described previously. Once you are satisfied that the fields have been mapped correctly and the model is correct, you can clear the "Load/import model" text box and click the "OK" button. When the transform is saved, the model will be stored in the XML configuration file or the repository (if one is being used).
4.2 Updating Incremental Models on the Incoming Data Stream
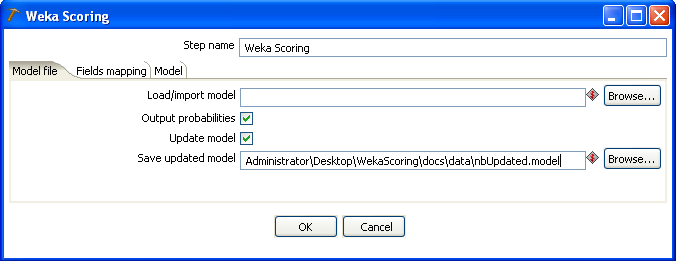
If the Weka model being used is an incremental one — that is, one that can be updated/trained on a row-by-row basis — then this can be turned on by selecting the "Update model" checkbox. Furthermore, the updated model can be saved to a file after the transform completes by providing a file name in the "Save updated model" text box.
Note
Only certain classifiers can be updated incrementally. The "Update model" checkbox and "Save updated model" text box will be grayed out if the loaded model is not incremental.
Note
An incremental classifier can only learn from incoming rows if there is a correctly mapped target/class column in the data and it contains non-missing values.
4.3 Using PMML Models
As of Weka version 3.6.0, certain types of models expressed in the Predictive Modeling Markup Language can be imported by Weka and by the Weka scoring plugin. Version 3.6.0 can import Regression, General regression and Neural Network models. 3.7.0 adds Tree models. Loading a PMML model file into the Weka scoring step is simply a matter of browsing to the location of the XML file that contains the model. Selecting "PMML model file" in the file type drop down box of the file chooser dialog will show all files with a ".xml" extension. Once loaded, the model can be used in exactly the same way as a Weka native model.
More information on PMML support in Weka, including a roadmap for development, can be found here.
5 Tips and Tricks
5.1 Maximizing Throughput
In order to maximize the data throughput in the Weka scoring step, it is necessary to understand how Weka represents attribute values internally. All values encapsulated in Weka's Instance class are stored in primative Java double floating point format. This is the case for integer, real and nominal (discrete) values. In the case of the latter, the value represents the index of the discrete value, stored in double floating point format. Maximum speed, when the scoring step converts Kettle rows to Weka Instances, will be achieved when the incoming Kettle rows contain values that are Numbers (Doubles) for all numeric fields and Strings for all discrete fields. Integers or Booleans will trigger a conversion to Double. When there are a lot of fields, this conversion will affect performance.
5.2 A Note About the CSV Input Step
Kettle's CSV input step has an option called "Lazy conversion". By default, lazy conversion is turned on. This means that fields are read from the csv file into byte arrays. Construction of objects that represent the correct type for a particular field only occurs when a Kettle step requests a particular value from a row of data. This makes reading rows of data from the csv file extremely fast, and little overhead is imposed as long as downstream steps are not requesting a lot of values from the data rows. In the case of the Weka scoring step, most, if not all, values in a row will need to be accessed in order to construct an Instance to pass to the classifier. When there are many attributes/fields this can result in a performance hit. Better performance can be achieved by turning off "Lazy conversion" in the CSV input step. This has the effect of making the CSV input step construct the correct type of object for a field as data is read in.