KnowledgeFlow plugin for Kettle (ETL + Data Mining)
- Former user (Deleted)
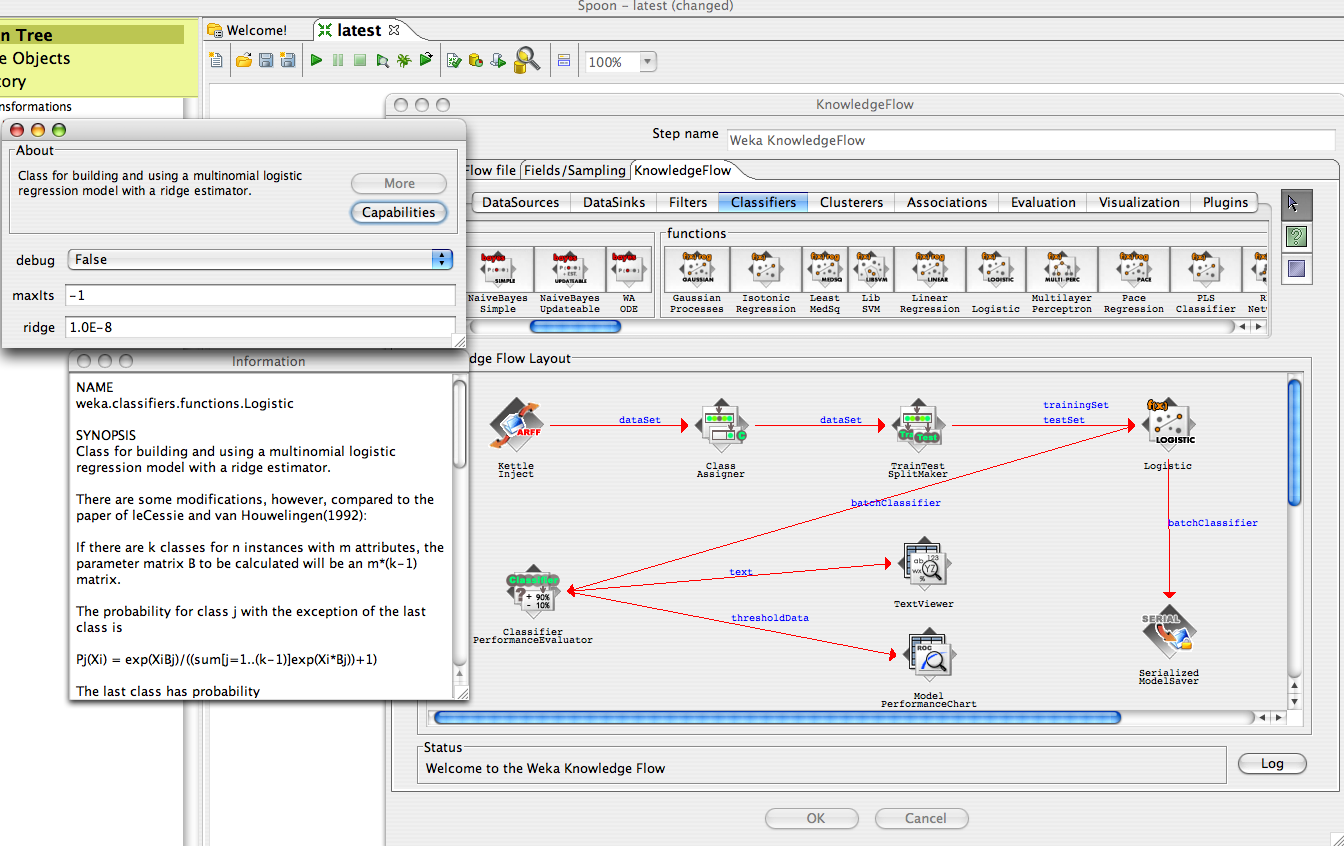
The KnowledgeFlow plugin for Pentaho Data Integration (Kettle) allows data mining processes to be run as part of an Kettle transform. The following example shows the configuration of the plugin with a data mining flow that learns a multinomial logistic regression model from data siphoned off from an ETL process. The logistic model is evaluated and the evaluation results are available for further processing by downstream Kettle steps. As part of the data mining flow, the learned logistic model is saved in serialized form to a file (for later use in a scoring process for example).
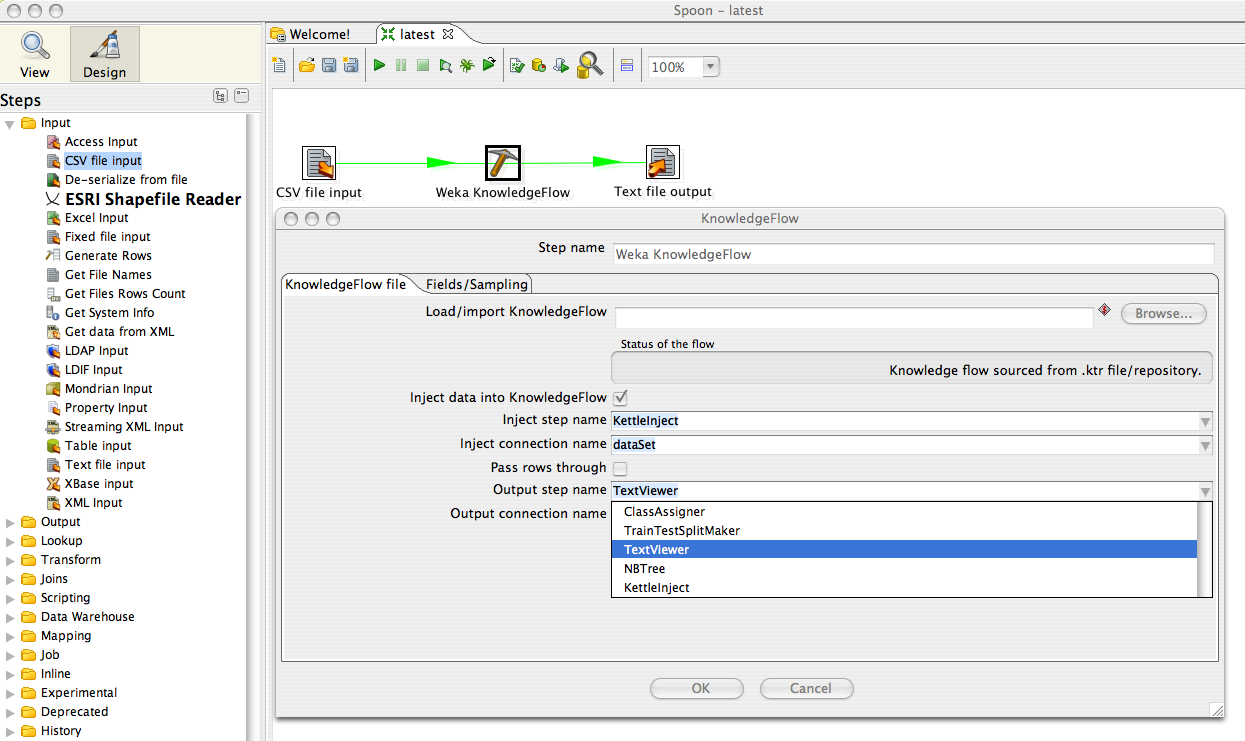
In this figure, the plugin is configured to feed incoming data into the data mining flow. A KnowledgeFlow step is chosen as the entry point for the data and a particular connection type is selected (the incoming Kettle data is converted into a "dataSet" for the mining flow). The figure also shows a particular KnowledgeFlow step being selected as a source of output from the mining process.
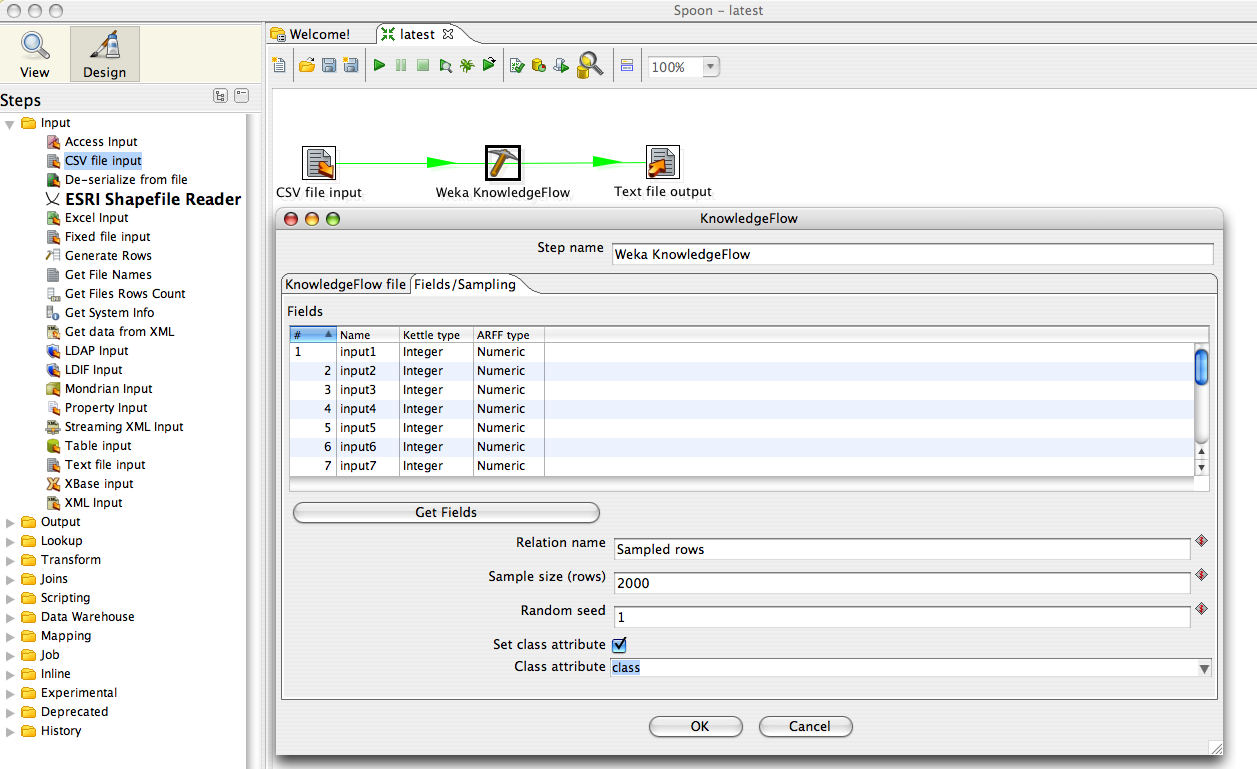
This next figure, shows the configuration of data mapping between Kettle and the KnowledgeFlow, and the selection of sampling parameters (reservoir sampling). Most Weka components operate on batches of data; some can operate in a true streaming fashion. Eventually, the KnowledgeFlow Kettle plugin will support streaming data to those Weka components that can handle data incrementally.
This figure shows the embedded KnowledgeFlow editor. The current data mining flow is displayed along with configuration and help panels for the logistic regression model.