Create Mapper and Reducer for Aggregate Dataset
- Former user (Deleted)
- Former user (Deleted)
Create a Pentaho Mapper Transformation
In this task you will create a Pentaho Mapper transformation. This transformation will be used to run a Pentaho MapReduce job on the Hadoop cluster. This transformation will consume a parsed, tab-delimited weblog record and construct intermediate data consisting of a key comprised of Client IP, Year, and Month and emitting a constant value of 1. The value denotes a single pageview for the key. The summing will be done by the Reducer – which we will develop next.
- Start PDI on your desktop. Once it is running choose 'File' -> 'New' -> 'Transformation' from the menu system or click on the 'New file' icon on the toolbar and choose the 'Transformation' option.
Speed Tip
You can download the Kettle Transform aggregate_mapper.ktr already completed
- Add a MapReduce Input Step: You are going to read data into the transformation from MapReduce, so expand the 'Big Data' section of the Design palette and drag a 'MapReduce Input' node onto the transformation canvas. Your transformation should look like:
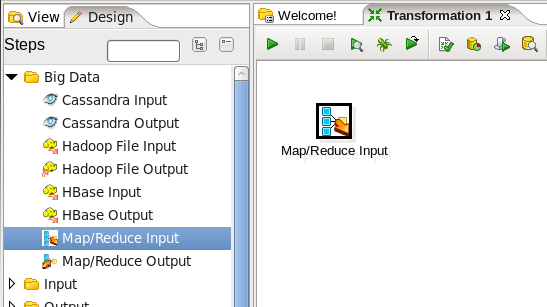
- Edit the MapReduce Input Step: Double-click on the 'MapReduce Input' node to edit its properties. Enter this information:
- Key Field Type: Enter String
- Value Field Type: Enter String
When you are done your 'MapReduce Input' window should look like this:
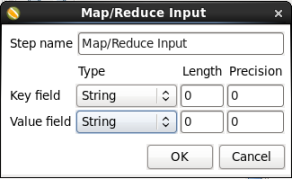
Click 'OK' to close the window.
- Add a Split Fields Step: You need to split the incoming records on tab to get the individual fields in the record, so expand the 'Transform' section of the Design palette and drag a 'Split Fields' node onto the transformation canvas. Your transformation should look like:
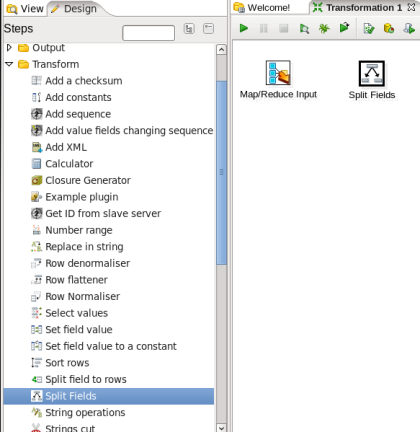
- Connect the Input and Split Fields Steps: Hover the mouse over the 'MapReduce Input' node and a tooltip will appear.
Click on the output connector (the green arrow pointing to the right) and drag a connector arrow to the 'Split Fields' node. Your canvas should look like this:
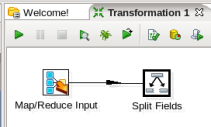
- Edit the Split Fields Step: Double-click on the 'Split Fields' node to edit its properties. Enter this information:
- Field to split: Select 'value'
- Delimiter: Enter '$[09]' 09 is the hexadecimal representation of the ASCII tab character.
- Fields: The field list will be the following of with 'Type' set to 'String'
- client_ip
- full_request_date
- day
- month
- month_num
- year
- hour
- minute
- second
- timezone
- http_verb
- uri
- http_status_code
- bytes_returned
- referrer
- user_agent
When you are done your 'MapReduce Input' window should look like this:
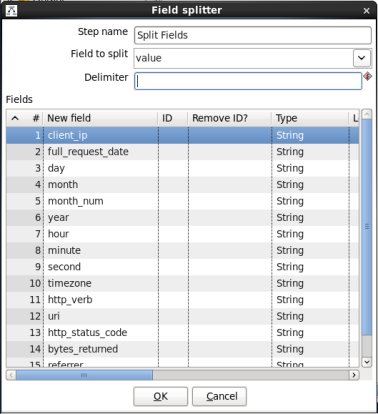
Click 'OK' to close the window.
- Add a User Defined Java Expression Step: You need to concatenate the client_ip, year, and month together to create the key field, so expand the 'Scripting' section of the Design palette and drag a 'User Defined Java Expression' node onto the transformation canvas. Your transformation should look like:
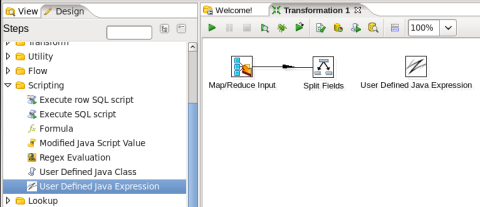
- Connect the Split Fields and User Defined Java Expression Steps: Hover the mouse over the 'Split Fields' node and a tooltip will appear. Click on the output connector (the green arrow pointing to the right) and drag a connector arrow to the 'User Defined Java Expression' node. Your canvas should look like this:
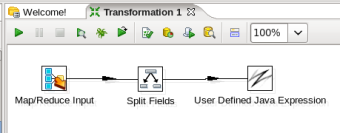
- Edit the User Defined Java Expression Step: Double-click on the 'User Defined Java Expression' node to edit its properties. Do the following:
- Create a new field 'new_key' with Type 'String' and the following Java expression:
Note the characters between the '' are tabs. You will have to copy and paste tab characters into the Java Expression.client_ip + '\t' + year + '\t' + month_num
- Create a new field 'new_value' with Type 'Integer' and the Java expression '1'.
When you are done your window should look like:
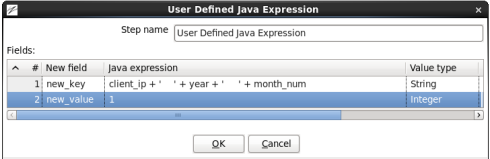
Click 'OK' to close the window.
- Create a new field 'new_key' with Type 'String' and the following Java expression:
- Add a MapReduce Output Step: You need to write the new key and new value to the output, so expand the 'Big Data' section of the Design palette and drag a 'MapReduce Output' node onto the transformation canvas. Your transformation should look like:
- Connect the Java Expression and Output Steps: Hover the mouse over the 'User Defined Java Expression' node and a tooltip will appear. Click on the output connector (the green arrow pointing to the right) and drag a connector arrow to the 'MapReduce Output' node. Your canvas should look like this:
- Edit the Output Step: Double-click on the 'MapReduce Output' node to edit its properties. Enter the following information:
- Key field: Select 'new_key'
- Value field: Select 'new_value'
When you are done your window should look like:
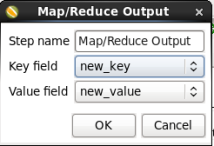
Click 'OK' to close the window.
- Save the Transformation: Choose 'File' -> 'Save as...' from the menu system. Save the transformation as 'aggregate_mapper.ktr' into a folder of your choice.
Create a Pentaho Reducer Transformation
In this task you will create a Pentaho reducer transformation. It will consume the output of the mapper you just created and emit the same key while summing the values. The emitted value will be the count of pageviews for the key. Note that we do not need to do any sorting in this transformation since we can rely on the MapReduce engine's sort and shuffle process to ensure that the reducer receive records sorted in key order.
- Start PDI on your desktop. Once it is running choose 'File' -> 'New' -> 'Transformation' from the menu system or click on the 'New file' icon on the toolbar and choose the 'Transformation' option.
Speed Tip
You can download the Kettle Transform aggregate_reducer.ktr already completed
- Add a MapReduce Input Step: You are going to read data into the transformation from MapReduce, so expand the 'Big Data' section of the Design palette and drag a 'MapReduce Input' node onto the transformation canvas. Your transformation should look like:
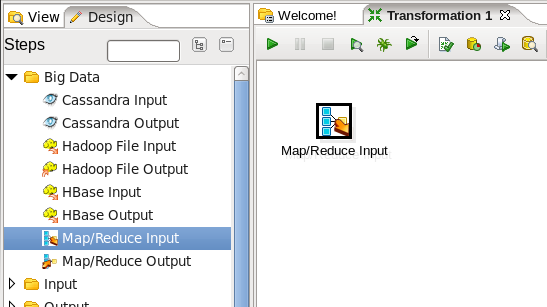
- Edit the MapReduce Input Step: Double-click on the 'MapReduce Input' node to edit its properties. Enter this information:
- Key Field Type: Enter 'String'
- Value Field Type: Enter 'Integer'
When you are done your 'MapReduce Input' window should look like this:
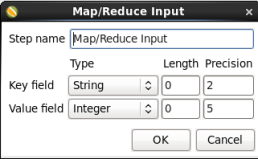
Click 'OK' to close the window.
- Add a Group By Step: You are going to sum the values for each key, so expand the 'Statistics' section of the Design palette and drag a 'Group by' node onto the transformation canvas. Your transformation should look like:
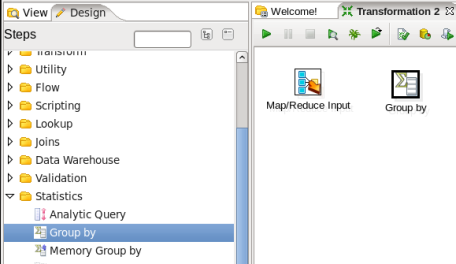
- Connect the Input and Group By Steps: Hover the mouse over the 'MapReduce Input' node and a tooltip will appear. Click on the output connector (the green arrow pointing to the right) and drag a connector arrow to the 'Group by' node. Your canvas should look like this:
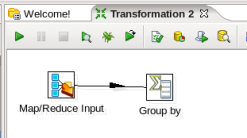
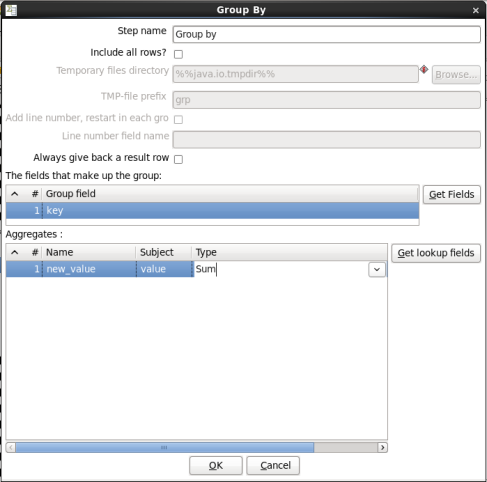
- Edit the Group By Step: Double-click on the 'Group by' node to edit its properties. Enter this information:
- Group field: Enter 'key'
- Aggregates: Enter the following:
- Name: Enter 'new_value'
- Subject: Enter 'value'
- Type: Select 'Sum'
When you are done your window should look like this:
Click 'OK' to close the window.
- Add a MapReduce Output Step: You need to write the new key and new value to the output, so expand the 'Big Data' section of the Design palette and drag a 'MapReduce Output' node onto the transformation canvas. Your transformation should look like:
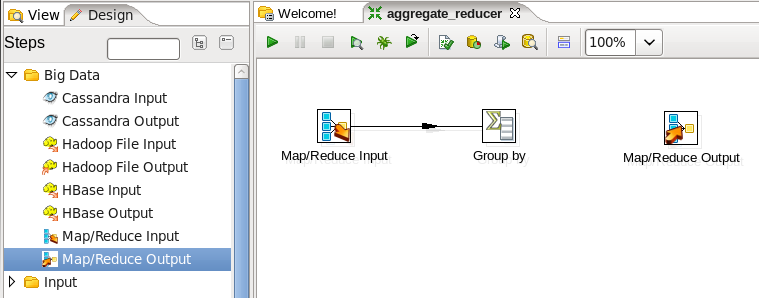
- Connect the Group By and Output steps: Hover the mouse over the 'Group by' node and a tooltip will appear. Click on the output connector (the green arrow pointing to the right) and drag a connector arrow to the 'MapReduce Output' node. Your canvas should look like this:
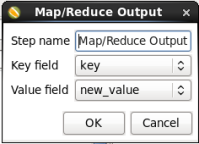
- Edit the Output Step: Double-click on the 'MapReduce Output' node to edit its properties. Enter the following information:
- Key field: Select 'key'
- Value field: Select 'new_value'
When you are done your window should look like:
Click 'OK' to close the window.
- Save the Transformation: Choose 'File' -> 'Save as...' from the menu system. Save the transformation as 'aggregate_reducer.ktr' into a folder of your choice.