Weka Execution in Hadoop
This is a production Pentaho Labs project

This project has made it into product and is supported. We are very interested in your feedback and your use cases.
A recipe for executing Weka in Hadoop.
Project Info
- Status: Compatible with Weka version: >= 3.7.10
- Roadmap: Future work - distributed clustering, distributed recommendation engine, pre-processing for text mining, oversampling for minority classes
- Availability: Open Source - Subversion - Install via Weka's package manager
- Contact: mhall or use "Add Comment" at bottom of page
- JIRA: http://jira.pentaho.com/browse/DATAMINING-608 http://jira.pentaho.com/browse/DATAMINING-609
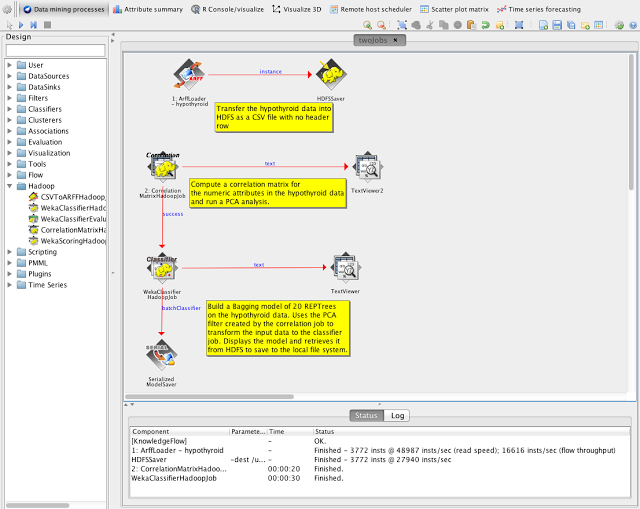
This package for Weka >= 3.7.10 provides several jobs for executing learning tasks inside of Hadoop. These include:
- Determining ARFF meta data and summary statisitics
- Computing a correlation or covariance matrix
- Training a Weka classifier or regressor
- Generating randomly shuffled (and stratified) input data chunks
- Evaluating a Weka classifier or regressor via cross-validation or a hold-out set
- Scoring using a training classifier or regressor
A full-featured command line interface is available along with GUI Knowledge Flow components for job orchestration. Predictive models learned in Hadoop are fully compatible with Pentaho Data Integration's "Weka Scoring" transformation step.
More information on what is available in the distributed Weka package, and how it is implemented, can be found in a three part blog posting:
Try it out!
Open Weka's package manager (GUIChooser->Tools->Package manager) and install "distributedWekaHadoop".