Using Pentaho MapReduce to Parse Weblog Data
- Former user (Deleted)
- Former user (Deleted)
- Former user (Deleted)
How to use Pentaho MapReduce to convert raw weblog data into parsed, delimited records.
The steps in this guide include
- Loading the sample data file into HDFS
- Developing a PDI transformation which will serve as a Mapper
- Developing a PDI job which will invoke a Pentaho MapReduce step that runs a map-only job, using the developed mapper transformation.
- Executing and reviewing output
Prerequisites
In order to follow along with this how-to guide you will need the following:
- Hadoop
- Pentaho Data Integration
- Pentaho Hadoop Node Distribution
Sample Files
The sample data file needed for this guide is:
File Name |
Content |
Unparsed, raw weblog data |
NOTE: If you have completed the Loading Data into HDFS guide, then the necessary file will already be in the proper location.
This file should be placed in HDFS at /user/pdi/weblogs/raw using the following commands.
hadoop fs -mkdir /user/pdi/weblogs hadoop fs -mkdir /user/pdi/weblogs/raw hadoop fs -put weblogs_rebuild.txt /user/pdi/weblogs/raw/
Step-By-Step Instructions
Setup
Start Hadoop if it is not already running.
Create a Mapper Transformation to Parse the Raw Weblog Data File
In this task you will create a mapper transformation that will parse the weblog file into an easier to use format.
Speed Tip
You can download the Kettle Transformation weblog_parse_mapper.ktr already completed
- Start PDI on your desktop. Once it is running choose 'File' -> 'New' -> 'Transformation' from the menu system or click on the 'New file' icon on the toolbar and choose the 'Transformation' option.
- Add a Map/Reduce Input Step: You are going to read data as a mapper transformation, so expand the 'Big Data' section of the Design palette and drag a 'Map/Reduce Input' node onto the transformation canvas. Your transformation should look like:
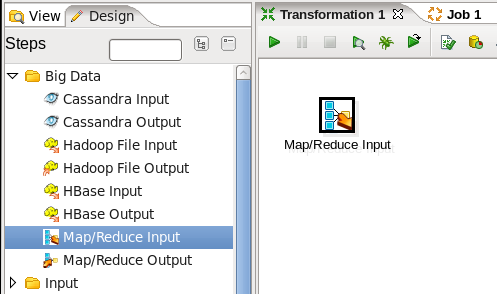
- Edit the Map/Reduce Input Step: Double-click on the 'Map/Reduce Input' node to edit its properties. Enter this information:
- Key Field Type: Enter String
- Value Field Type: Enter String
When you are done your 'Map/Reduce Input' window should look like this:
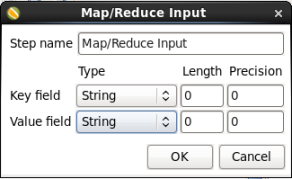
Click 'OK' to close the window.
- Add a Regex Evaluation Step: You need to parse the record using a regular expression to get the information from the web log, so expand the 'Scripting' section of the Design palette and drag a 'Regex Evaluation' node onto the transformation canvas. Your transformation should look like:
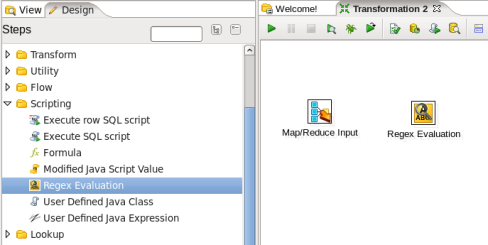
- Connect the Input and Regex Evaluation Steps: Hover the mouse over the 'Map/Reduce Input' node and a tooltip will appear. Click on the output connector (the green arrow pointing to the right) and drag a connector arrow to the 'Regex Evaluation' node. Your canvas should look like this:
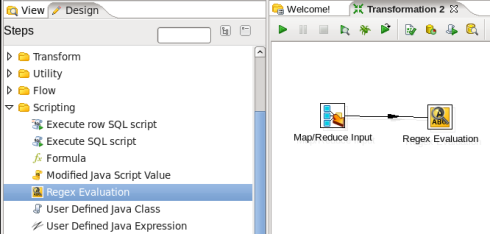
- Edit the Regex Evaluation Step: Double-click on the 'Regex Evaluation' node to edit its properties. Enter this information:
- Field to evaluate: Enter 'value'
- Result Fieldname: Enter 'is_match'
- Check 'Create fields for capture groups'
- Regular Expression: Enter
^([^\s]{7,15})\s # client_ip -\s # unused IDENT field -\s # unused USER field \[((\d{2})/(\w{3})/(\d{4}) # request date dd/MMM/yyyy :(\d{2}):(\d{2}):(\d{2})\s([-+ ]\d{4}))\] # request time :HH:mm:ss -0800 \s"(GET|POST)\s # HTTP verb ([^\s]*) # HTTP URI \sHTTP/1\.[01]"\s # HTTP version (\d{3})\s # HTTP status code (\d+)\s # bytes returned "([^"]+)"\s # referrer field " # User agent parsing, always quoted. "? # Sometimes if the user spoofs the user_agent, they incorrectly quote it. ( # The UA string [^"]*? # Uninteresting bits (?: (?: rv: # Beginning of the gecko engine version token (?=[^;)]{3,15}[;)]) # ensure version string size ( # Whole gecko version (\d{1,2}) # version_component_major \.(\d{1,2}[^.;)]{0,8}) # version_component_minor (?:\.(\d{1,2}[^.;)]{0,8}))? # version_component_a (?:\.(\d{1,2}[^.;)]{0,8}))? # version_component_b ) [^"]* # More uninteresting bits ) | [^"]* # More uninteresting bits ) ) # End of UA string "? " - Capture Group Fields: Add the following all with Type String
- client_ip
- full_request_date
- day
- month
- year
- hour
- minute
- second
- timezone
- http_verb
- uri
- http_status_code
- bytes_returned
- referrer
- user_agent
- firefox_gecko_version
- firefox_gecko_version_major
- firefox_gecko_version_minor
- firefox_gecko_version_a
- firefox_gecko_version_b
When you are done your 'Regex Evaluation' window should look like this:
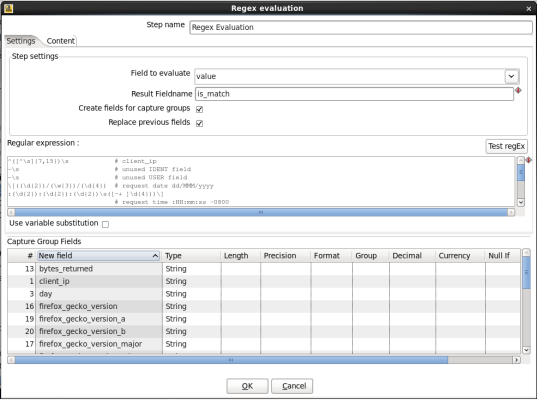
- Permit whitespace and comments in regular expression: Switch to the 'Content' tab and check the 'Permit whitespace and comments in pattern' option. When you are done your window should look like:
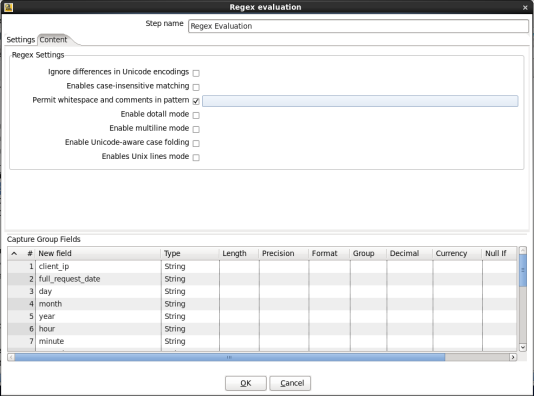
Click 'OK' to close the window.
- Add a Filter Rows Step: You should always ensure you do not have any bad rows in your file that may break future processing, so expand the 'Flow' section of the Design palette and drag a 'Filter Rows' node onto the transformation canvas. Your transformation should look like:
- Connect the Regex Evaluation and Filter Rows Steps: Hover the mouse over the 'Regex Evaluation' node and a tooltip will appear. Click on the output connector (the green arrow pointing to the right) and drag a connector arrow to the 'Filter Rows' node. Your canvas should look like this:
- Edit the Filter Rows Step: Double-click on the 'Filter Rows' node to edit its properties. Enter this information:
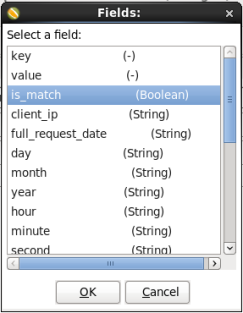
- Click the <field> box to the left of the '=' box
- A 'Select a field:' window will appear. Select 'is_match' and click 'OK'.
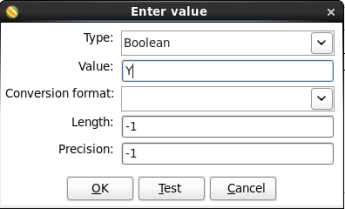
- Click the <value> box
- A 'Enter value' box will appear. Enter 'Y' for Value and click 'OK'.
When you are done your window should look like:
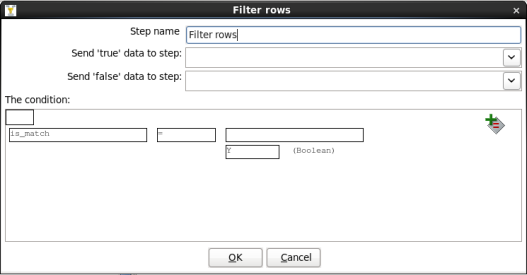
Click 'OK' to close the window.
- Add a Value Mapper Step: You may want to be able to use the month number instead of the 3 letter month, so expand the 'Transform' section of the Design palette and drag a 'Value Mapper' node onto the transformation canvas. Your transformation should look like:
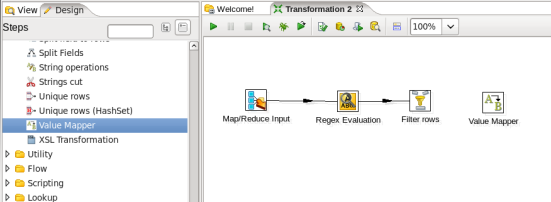
- Connect the Filter Rows and Value Mapper Steps: Hover the mouse over the 'Filter Rows' node and a tooltip will appear. Click on the output connector (the green arrow pointing to the right) and drag a connector arrow to the 'Value Mapper' node. When you release the mouse and a window appears
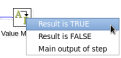 select the 'Result is TRUE' option. Your canvas should look like this:
select the 'Result is TRUE' option. Your canvas should look like this:
- Edit the Value Mapper Step: Double-click on the 'Value Mapper' node to edit its properties. Enter this information:
- Fieldname to use: Select 'month'
- Target field name: Enter 'month_num'
- Default upon non-matching: Enter '0'
- Field Values: Enter the following:
Source Value
Target Value
Jan
1
Feb
2
Mar
3
Apr
4
May
5
Jun
6
Jul
7
Aug
8
Sep
9
Oct
10
Nov
11
Dec
12
When you are done your window should look like:
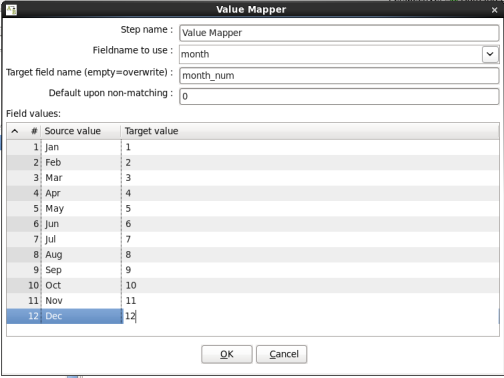
Click 'OK' to close the window.
- Add a Dummy Step: You always have to tell a Filter Rows node what to do with the rows that do not match, in this case we do not want to do anything with them, so expand the 'Flow' section of the Design palette and drag a 'Dummy (do nothing)' node onto the transformation canvas. Your transformation should look like:
- Connect the Filter Rows and Dummy Steps: Hover the mouse over the 'Filter Rows' node and a tooltip will appear. Click on the output connector (the green arrow pointing to the right) and drag a connector arrow to the 'Dummy (do nothing)' node. When you release the mouse and a window appears. Select the 'Result is FALSE option. Your canvas should look like this:
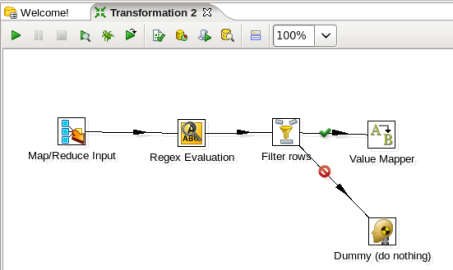
- Add a User Defined Java Expression Step: You need to concatenate your output fields together as a mapper transformation may only have two output fields a key and a value, so expand the 'Scripting' section of the Design palette and drag a 'User Defined Java Expression' node onto the transformation canvas. Your transformation should look like:
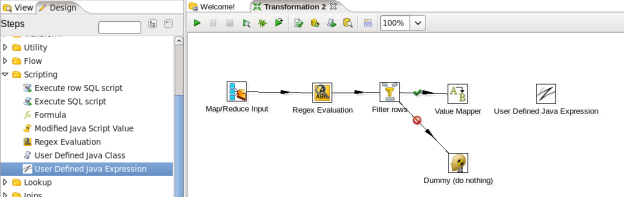
- Connect the Value Mapper and Java Expression Steps: Hover the mouse over the 'Value Mapper' node and a tooltip will appear. Click on the output connector (the green arrow pointing to the right) and drag a connector arrow to the 'User Defined Java Expression' node. Your canvas should look like this:
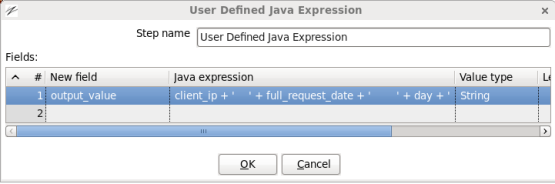
- Edit the User Defined Java Expression Step: Double-click on the 'User Defined Java Expression' node to edit its properties. Enter this information:
- New field: Enter 'output_value'
- Java Expression: Enter
client_ip + '\t' + full_request_date + '\t' + day + '\t' + month + '\t' + month_num + '\t' + year + '\t' + hour + '\t' + minute + '\t' + second + '\t' + timezone + '\t' + http_verb + '\t' + uri + '\t' + http_status_code + '\t' + bytes_returned + '\t' + referrer + '\t' + user_agent
- Value Type: Select 'String'
When you are done your window should look like:
Click 'OK' to close the window.
- Add a Map/Reduce Output Step: You need to output your results to the Map/Reduce framework, so expand the 'Big Data' section of the Design palette and drag a 'Map/Reduce Output' node onto the transformation canvas. Your transformation should look like:
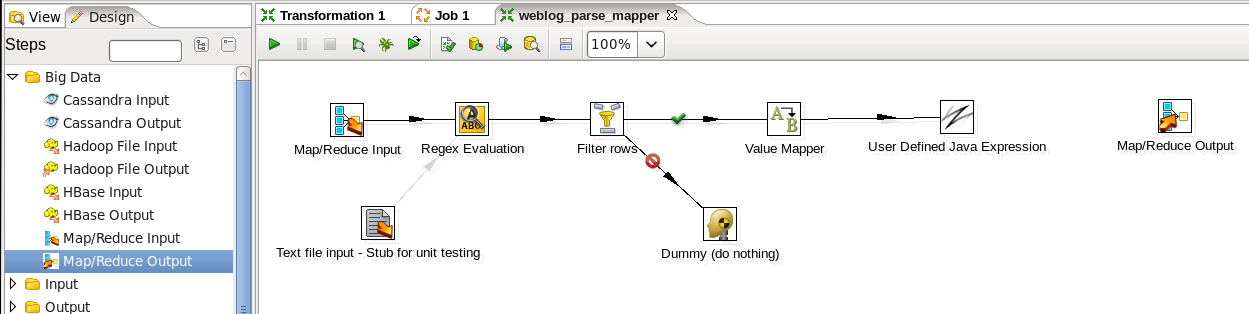
- Connect the Java Expression and Output Steps: Hover the mouse over the 'User Defined Java Expression' node and a tooltip will appear. Click on the output connector (the green arrow pointing to the right) and drag a connector arrow to the 'Map/Reduce Output' node. Your canvas should look like this:
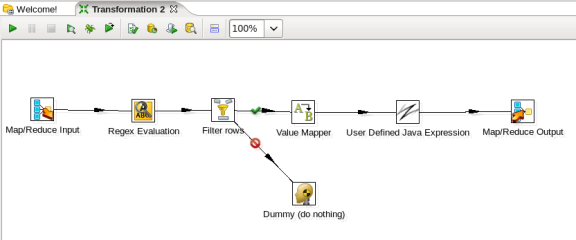
- Edit the Output Step: Double-click on the 'Map/Reduce Output' node to edit its properties. Enter this information:
- Key field: Select 'key'
- Value field: select 'output_value'
When you are done your window should look like:
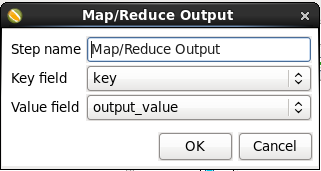
Click 'OK' to close the window.
- Save the Transformation: Choose 'File' -> 'Save as...' from the menu system. Save the transformation as 'weblog_parse_mapper.ktr' into a folder of your choice.
Create a PDI Job to Execute a Map Only MapReduce Process
In this task you will create a job that will execute a "map-only" MapReduce process using the mapper transformation you created in the previous section.
Speed Tip
You can download the Kettle Job weblog_parse_mr.kjb already completed
- Within PDI, choose 'File' -> 'New' -> 'Job' from the menu system or click on the 'New file' icon on the toolbar and choose the 'Job' option.
- Add a Start Job Entry: You need to tell PDI where to start the job, so expand the 'General' section of the Design palette and drag a 'Start' node onto the job canvas. Your canvas should look like:
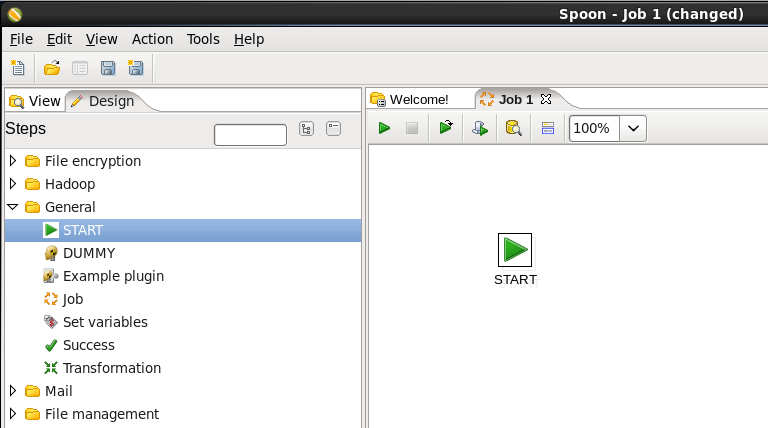
- Add a Pentaho MapReduce Job Entry: Expand the 'Big Data' section of the Design palette and drag a 'Pentaho MapReduce' job entry onto the job canvas. Your canvas should look like:
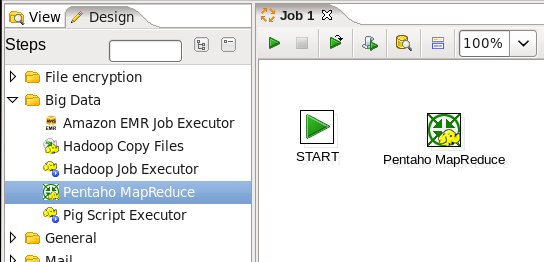
- Connect the Start and MapReduce Job Entries: Hover the mouse over the 'Delete folders' job entry and a tooltip will appear. Click on the output connector (the green arrow pointing to the right) and drag a connector arrow to the 'Pentaho MapReduce' job entry.
Your canvas should look like this:
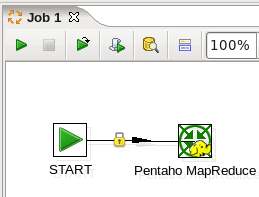
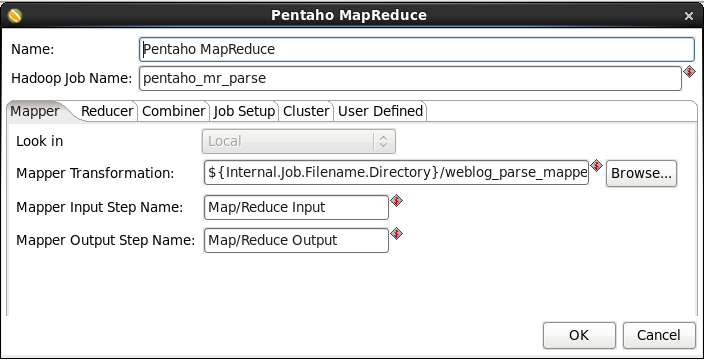
- Edit the MapReduce Job Entry: Double-click on the 'Pentaho MapReduce' job entry to edit its properties. Enter this information:
- Hadoop Job Name: Enter 'Web Log Parser'
- Mapper Transformation: Enter <PATH>/weblog _parse_mapper.ktr
<PATH> is the folder path you saved the mapper in. - Mapper Input Step Name: Enter 'MapReduce Input'
- Mapper Output Step Name: Enter 'MapReduce Output'
When you are done the window should look like:
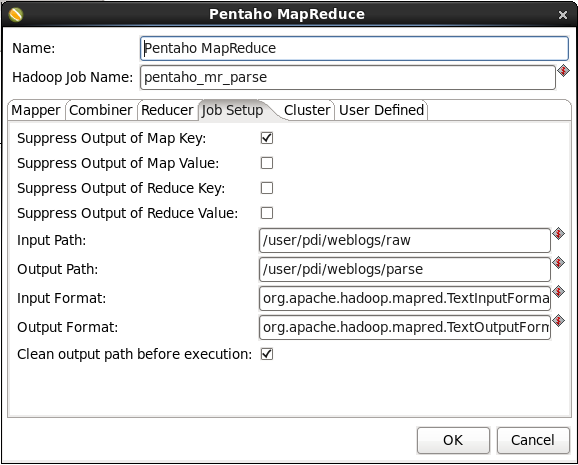
- Configure the MapReduce Job: Switch to the 'Job Setup' tab. Enter this information:
- Check 'Suppress Output of Map Key'
- Input Path: Enter '/user/pdi/weblogs/raw'
- Output Path: Enter '/user/pdi/weblogs/parse'
- Input Format: Enter 'org.apache.hadoop.mapred.TextInputFormat'
- Output Format: Enter 'org.apache.hadoop.mapred.TextOutputFormat'
- Check 'Clean output path before execution'
When you are done your window should look like:
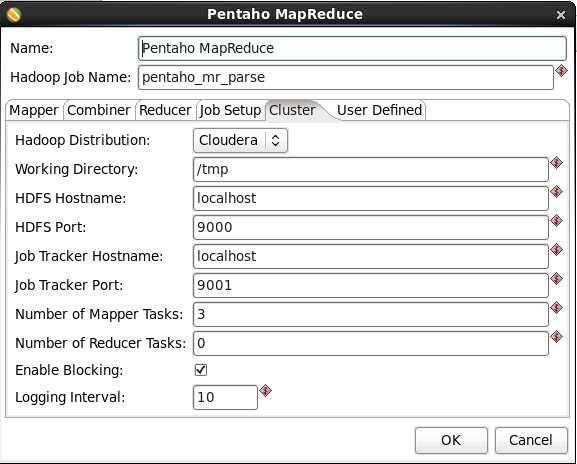
- Configure the Cluster Properties: Switch to the 'Cluster' tab. Enter this information:
- Hadoop distribution: Select your Hadoop Distribution
- Working Directory: Enter '/tmp'
- HDFS Hostname, HDFS Port, Job Tracker Hostname, Job Tracker Port: Your connection information.
- Number of Mapper Tasks: Enter '3'. You can play around with this to get the best performance based on the size of your data and the number of nodes in your cluster.
- Number of Reducer Tasks: Enter '0'
- Check 'Enable Blocking'
- Logging Interval: Enter '10'. The number of seconds between pinging Hadoop for completion status messages
When you are done your window should look like:
Click 'OK' to close the window.
- Save the Job: Choose 'File' -> 'Save as...' from the menu system. Save the transformation as 'weblogs_parse_mr.kjb' into a folder of your choice.
- Run the Job: Choose 'Action' -> 'Run' from the menu system or click on the green run button on the job toolbar. An 'Execute a job' window will open. Click on the 'Launch' button. An 'Execution Results' panel will open at the bottom of the PDI window and it will show you the progress of the job as it runs. After a few seconds the job should finish successfully:
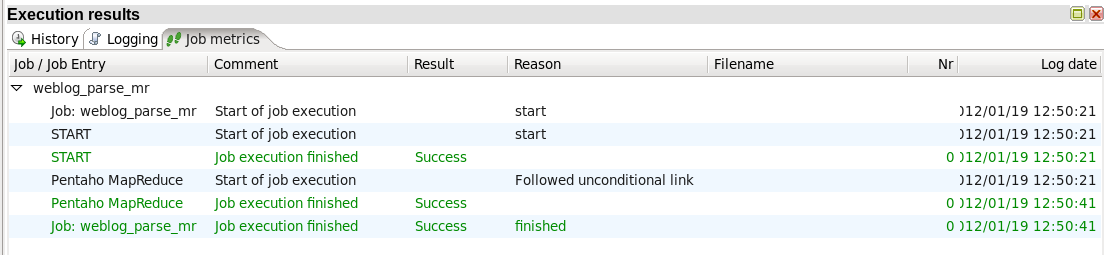
If any errors occurred the job entry that failed will be highlighted in red and you can use the 'Logging' tab to view error messages.
Check Hadoop for Parsed Weblog Data
- Run the following command to check the cluster for the parsed files:
hadoop fs -ls /user/pdi/weblogs/parse
This should return:
-rwxrwxrwx 3 demo demo 27132365 2012-01-04 16:52 /weblogs/parse/part-00001
-rwxrwxrwx 3 demo demo 0 2012-01-04 16:52 /weblogs/parse/_SUCCESS
-rwxrwxrwx 3 demo demo 27188268 2012-01-04 16:52 /weblogs/parse/part-00002
drwxrwxrwx - demo demo 1 2012-01-04 16:52 /weblogs/parse/_logs
-rwxrwxrwx 3 demo demo 27147417 2012-01-04 16:52 /weblogs/parse/part-00000
Summary
During this guide you learned how to create and execute a Pentaho MapReduce job to parse raw weblog data.