NOTE: |
|---|
This page references documentation for Pentaho, version 5.4.x and earlier. To see help for Pentaho 6.0.x or later, visit Pentaho Help. |
Architecture
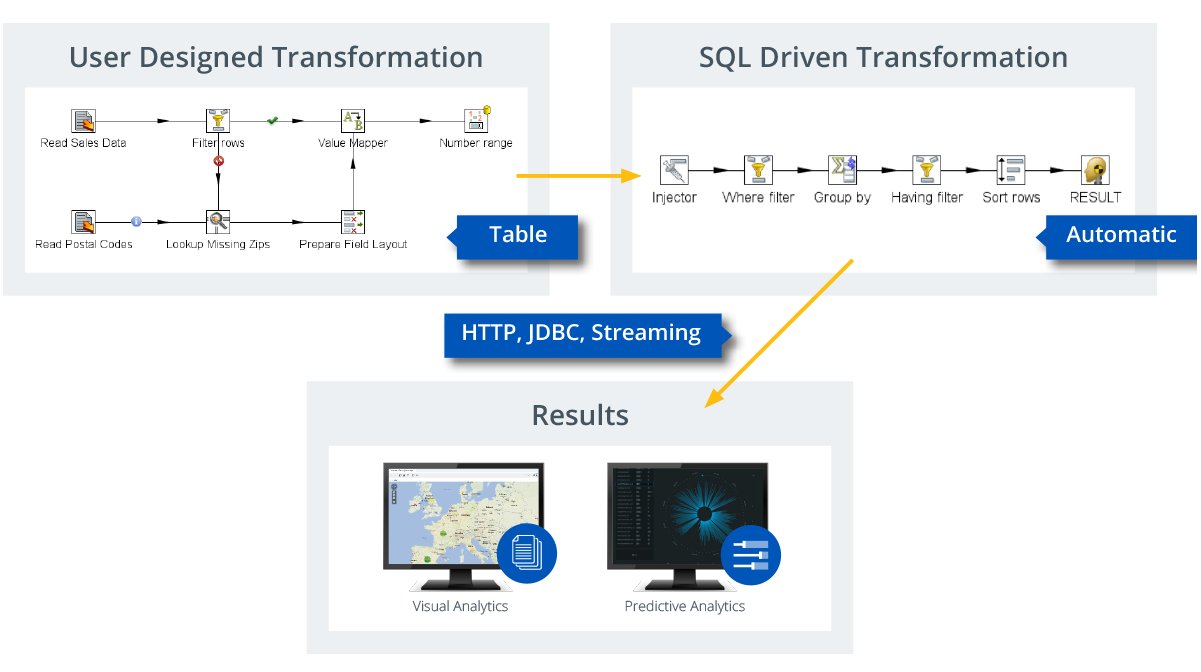
The main problem we faced early on was that the default language used under the covers, in just about any business intelligence user facing tool, is SQL. At first glance it seems that the worlds of data integration and SQL are not compatible. In Data Integration we read from a multitude of data sources, such as databases, spreadsheets, NoSQL and Big Data sources, XML and JSON files, web services and much more. However, SQL itself is a mini-ETL environment on its own as it selects, filters, counts and aggregates data. So we figured that it might be easiest if we would translate the SQL used by the various BI tools into Pentaho Data Integration transformations. This way, Pentaho Data Integration is doing what it does best, not directed by manually designed transformations but by SQL. This is at the heart of the Pentaho Data Blending solution.
As with most JDBC drivers, there is a server and a client component to the JDBC driver. The server is designed to run as a Servlet on the Carte server or the Pentaho Data Integration server.
To ensure that the automatic part of the data chain doesn’t become an impossible to figure out black box, Pentaho made once more good use of existing PDI technologies. All executed queries are logged on the Data Integration server (or Carte server) so you have a full view of all the work being done:
![]()
Server Execution and Monitoring
During execution of a query, 2 transformations will be executed on the server:
- A service transformation, of human design built in Spoon to provide the service data
- An automatically generated transformation to aggregate, sort and filter the data according to the SQL query
These 2 transformations will be visible on Carte or in Spoon in the slave server monitor and can be tracked, sniff tested, paused and stopped just like any other transformation. However, it will not be possible to restart them manually since both transformations are programatically linked.
Where are the data service tables coming from?
You can configure a transformation step to serve as a data service in the "Data Service" tab of the transformation settings dialog: 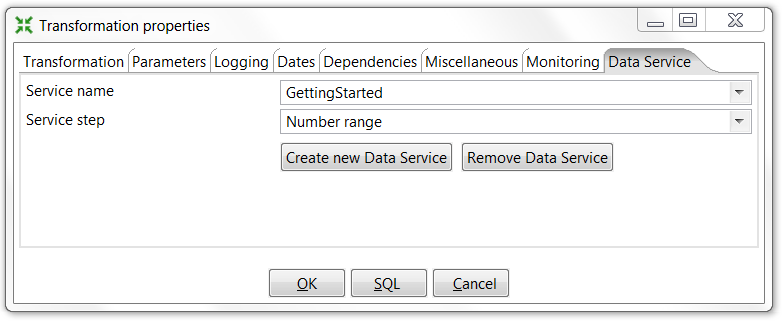
When such a transformation gets saved there is a new entry created in either the local metastore (under the .pentaho/metastore folder) or in the Enterprise repository on the DI server (in the internal /etc/metastore).
As such, Carte or the DI Server will automatically and immediately pick up newly configured data services from the moment your service transformation is saved.
The carte configuration file accepts a <repository> which will also be scanned in addition to the local metastore.
Reminder: the Carte users and passwords are stored in the pwd/kettle.pwd file and the default user is "cluster" with password "cluster". For the DI server you can use the standard admin or suzy accounts to test with password "password"
More details and setup-instructions can be found in: Configuration of the Thin Kettle JDBC driver