Introduction
In version 3.0 of Pentaho Data Integration we allow you to execute a job you defined on a (remote) slave server. This page explains how to set this up and what to look out for.
Basics
In a typical ETL setup, you might come across the need to fire off a job on a remote server somewhere. Version 3.0 of PDI is the first one to allow this.
Here is how you do it: you define a Slave Server in your job and specify the slave server on which you want to run the job on like this:
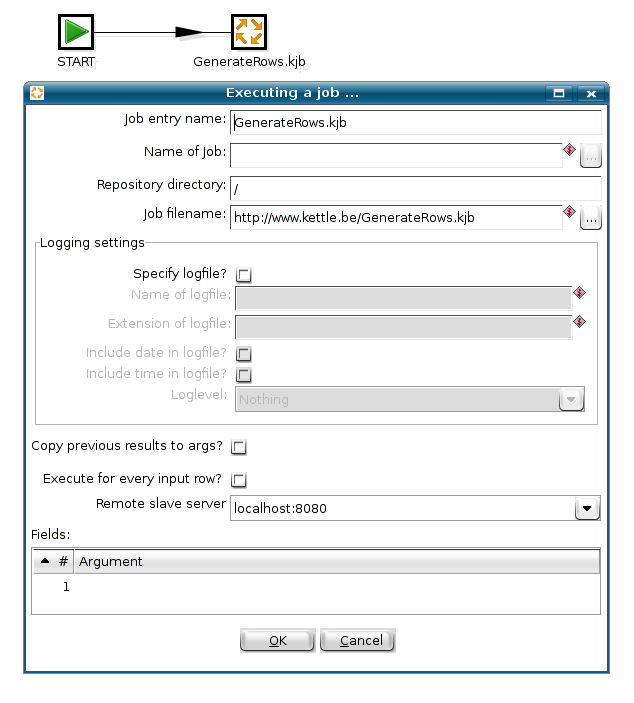
Possible problems
Referenced objects are not found
One of the first problems you will encounter is that ONLY the job itself is sent to the slave server for execution, not the referenced files, transformation, mappings, sub-jobs, etc.
SOLUTION 1: specify the correct files as they exist on the remote system. It might be tricky to test your jobs and transformations locally.
SOLUTION 2: Use a shared drive that is mapped locally and remotely so that you can make changes to the transformations and jobs easily. The drawback is that it's usually a hassle to set this up or to make sure the referenced paths are exactly the same on the remote system. (drive letters, mount paths, etc). If you do use this system, we make it easy for you because the referenced path of the local job file is send to the slave server for reference.
SOLUTION 3: Put all the referenced files into a zip file, let's call it "bigjob.zip". Reference all files relative to on another using variables like "Internal.Job.Filename.Directory" or ${Internal.Transformation.Filename.Directory}
That way you just have to transfer the file to the remote server (FTP, SFTP, etc). You can specify the location of the root job like this:
zip:file:///tmp/bigjob.zip!/MainJob.kjb
Note that the zip file can be located anywhere, even on a web server. The URL for the root job then simply changes to:
zip:http://ww.foo.com/bar/bigjob.zip!/MainJob.kjb