Introduction
Job restartability was introduced in PDI 5.0 to allow ETL developers to automatically skip over successfully executed parts of a job after a previously failed run.
Use Cases
Picture a hypothetical ETL workflow run nightly by a corporate headquarters. The workflow executes a transformation to update the stores table first, then a transformation to pull down and update sales data for each store, next a transformation to update inventory counts based on sales, and finally, a report for low inventory so orders and shipments can be arranged.
If any of these steps fail, it is likely that the job could be restarted at that point rather than re-running any of the earlier steps again. In this case, checkpointing would potentially provide a big benefit to the ETL maintainer and operations team.
On the other hand, if the steps that handle sales data and inventory counts are always sourcing "live" data, checkpointing might cause issues. If the job failed during the inventory update due to a database table permission issue, and the sales data step was checkpointed, the subsequent run of the job might pull in new inventory data that is out of sync with the previously executed sales data. The ETL designer should consider their ETL workflow and determine how checkpointing might interact to determine whether checkpoints can be used and after which steps.
Checkpoint log table
To keep track of the various execution attempts inside a single run of a job, we need a checkpoint log table.
You can find the definition of the checkpoint log table in the log tab of the job settings dialog.
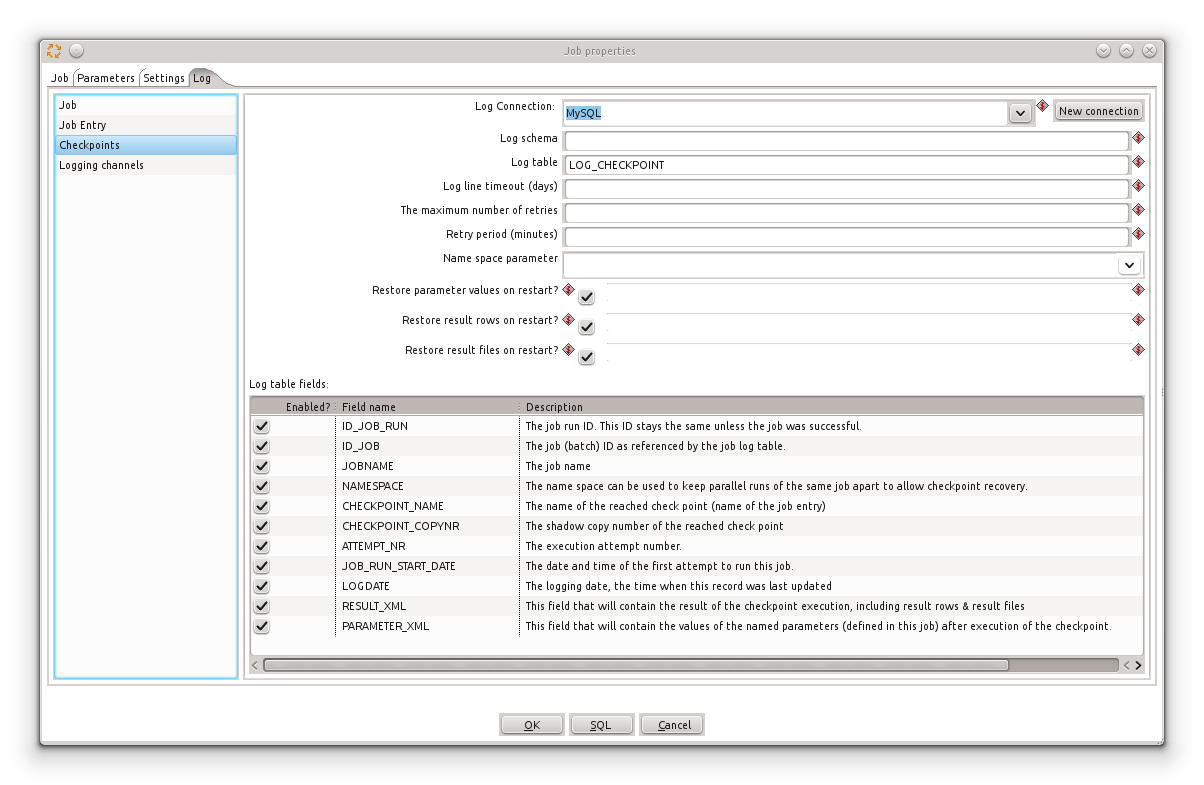
Checkpoint job entry
Every job entry in a job is capable of becoming a checkpoint. You can simply right click click on the job entry and enable the "checkpoint" option.
The fact that a job entry is a checkpoint is represented by a checkered flag placed on the outgoing hops:
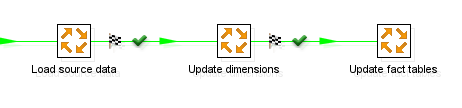
Please note that the flag is placed on the outgoing hops because the checkpoint job entry itself is not be executed when the job will be restarted. If the job uses the last reached checkpoint to start from, a flag is indicated where you would otherwise expect on OK or failed icon:

The checkpoint log table
The checkpoint log table contains all the fields required to keep track of the re-start behavior. For example, if we already tried 4 times to update the data warehouse and we had a failure each time, this is what we will find:
select ID_JOB_RUN, JOBNAME, NAMESPACE, CHECKPOINT_NAME, ATTEMPT_NR, JOB_RUN_START_DATE, LOGDATE from LOG_CHECKPOINT;select ID_JOB_RUN, JOBNAME, NAMESPACE, CHECKPOINT_NAME, ATTEMPT_NR, JOB_RUN_START_DATE, LOGDATE from LOG_CHECKPOINT; +------------+---------------------+-----------+------------------+------------+---------------------+---------------------+ | ID_JOB_RUN | JOBNAME | NAMESPACE | CHECKPOINT_NAME | ATTEMPT_NR | JOB_RUN_START_DATE | LOGDATE | +------------+---------------------+-----------+------------------+------------+---------------------+---------------------+ | 4 | Load data warehouse | - | Load source data | 4 | 2012-08-30 18:05:13 | 2012-08-30 18:17:10 | +------------+---------------------+-----------+------------------+------------+---------------------+---------------------+
If we subsequently fix the "Update dimensions step" and run the job again the job has advanced :

Now the checkpoint log table will contain the following:
select ID_JOB_RUN, JOBNAME, NAMESPACE, CHECKPOINT_NAME, ATTEMPT_NR, JOB_RUN_START_DATE, LOGDATE from LOG_CHECKPOINT; +------------+---------------------+-----------+-------------------+------------+---------------------+---------------------+ | ID_JOB_RUN | JOBNAME | NAMESPACE | CHECKPOINT_NAME | ATTEMPT_NR | JOB_RUN_START_DATE | LOGDATE | +------------+---------------------+-----------+-------------------+------------+---------------------+---------------------+ | 4 | Load data warehouse | - | Update dimensions | 7 | 2012-08-30 18:05:13 | 2012-08-30 21:43:45 | +------------+---------------------+-----------+-------------------+------------+---------------------+---------------------+
As you can see the checkpoint table was updated once more when the "Update dimensions" checkpoint job entry was reached.
Finally, the jobs is fixed and completely runs as planned:

Once that happens, the checkpoint name field in the logging table is cleared:
select ID_JOB_RUN, JOBNAME, NAMESPACE, CHECKPOINT_NAME, ATTEMPT_NR, JOB_RUN_START_DATE, LOGDATE from LOG_CHECKPOINT; +------------+---------------------+-----------+-----------------+------------+---------------------+---------------------+ | ID_JOB_RUN | JOBNAME | NAMESPACE | CHECKPOINT_NAME | ATTEMPT_NR | JOB_RUN_START_DATE | LOGDATE | +------------+---------------------+-----------+-----------------+------------+---------------------+---------------------+ | 4 | Load data warehouse | - | NULL | 8 | 2012-08-30 18:05:13 | 2012-08-30 22:35:04 | +------------+---------------------+-----------+-----------------+------------+---------------------+---------------------+
If we then run the complete job again, it starts from the beginning again with a new run ID (ID_JOB_RUN):
select ID_JOB_RUN, JOBNAME, NAMESPACE, CHECKPOINT_NAME, ATTEMPT_NR, JOB_RUN_START_DATE, LOGDATE from LOG_CHECKPOINT; +------------+---------------------+-----------+-----------------+------------+---------------------+---------------------+ | ID_JOB_RUN | JOBNAME | NAMESPACE | CHECKPOINT_NAME | ATTEMPT_NR | JOB_RUN_START_DATE | LOGDATE | +------------+---------------------+-----------+-----------------+------------+---------------------+---------------------+ | 4 | Load data warehouse | - | NULL | 8 | 2012-08-30 18:05:13 | 2012-08-30 22:35:04 | | 5 | Load data warehouse | - | NULL | 1 | 2012-08-31 00:08:13 | 2012-08-31 00:08:17 | +------------+---------------------+-----------+-----------------+------------+---------------------+---------------------+
Maximum retry count and period
In the checkpoint log table settings you will find 2 options to configure retry behavior:
- The maximum number of retries: this is the maximum amount of attempts that is allowed before giving up.
- Retry period (minutes): the period (in minutes counting after the first attempt) in which the job can be retried before giving up.
For example the retry period is important if you want to checkpoint data staging. You don't want to go back to the source system every time you start a job. However, after a certain period (24 hours or 1440 minutes) you will need to take action since your staged source data is stale.
The job will immediately throw an error and won't start in case the specified maximum number of attempts has been reached or if the retry period was exceeded.
This means that you have to clear out the log records before you can even attempt to run the job again.
Namespaces
In case you want to run the same job in parallel and want to automate automatic try/retry scenarios (across a set of parallel servers for example) you can assign a unique value to a parameter, defined in the job. This parameter can then be selected as the "name space parameter".
For example, while processing files in parallel you can process the file in a job in parallel with other files. A FILENAME parameter can then be used to separate one file from the other. If a file already was processed and encountered an error it will be retried.
Ignoring the last checkpoint
When you execute a job using Kitchen, you can use the following option to ignore the last reached checkpoint and to force the execution of a job to start at the "Start" job entry:
-custom:IgnoreCheckpoints=true
Alternatively you can modify the checkpoint log table yourself simply by executing a little bit of SQL.
To clear out all checkpoints for all jobs:
update LOG_CHECKPOINT set CHECKPOINT_NAME=null;
To clear the checkpoint for a specific job:
update LOG_CHECKPOINT set CHECKPOINT_NAME=null where JOB_NAME = 'Load data warehouse';
Internal Variables
In a job, internal variables are automatically set with respect to checkpoints:
- Internal.Job.Run.ID : this variables gives you the run ID (ID_JOB_RUN)
- Internal.Job.Run.AttemptNr: this gives you the attempt number (ATTEMPT_NR)