Description
The step inserts/updates objects on the OpenERP server in bulk using the 'import_data' function. The same import function used by the OpenERP GTK client. The only exception to using the import function is when the Return ID option is selected. All new rows (rows that failed the lookup) are created individually using the 'create' function on the OpenERP server. The create function returns the ID that we need to return to the output stream.
Since: PDI version 5.0 (PDI-6684)
Options
Option |
Description |
|---|---|
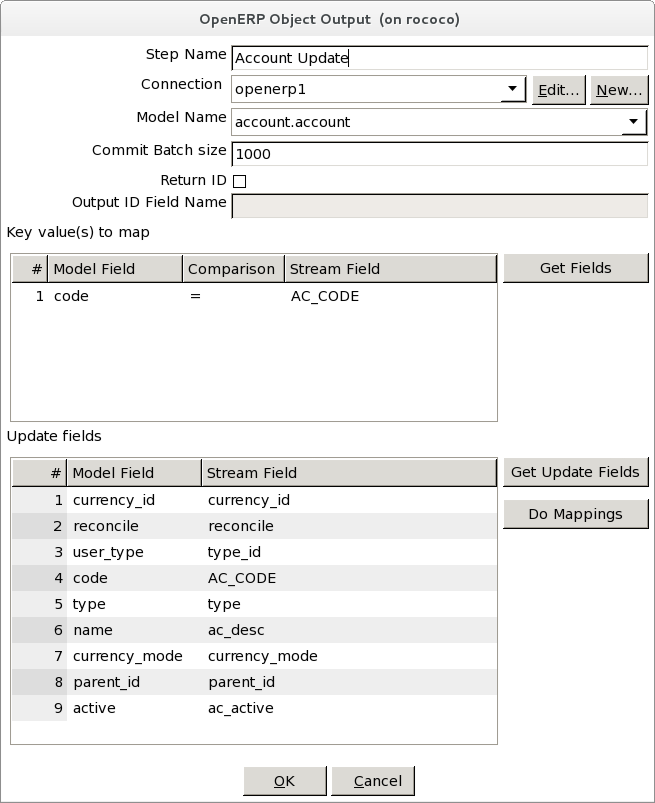
Step Name |
Name of the step; the name has to be unique in a single transformation. |
Connection |
The OpenERP database connection to write data to. |
Model Name |
Model/Object name to create/update data for |
Commit Batch Size |
Maximum number of records that will be batched into a call to the OpenERP server. |
Return ID |
If selected, the ID field is appended to the output stream. If you don't need it, don't select it as it will slow down the transformation. |
Output ID Name |
If the Return ID is selected, this field specifies the output field name that the object ID will be copied to. |
Key value fields |
Maps key object fields to the corresponding stream fields. If no fields are specified, all rows are handled as new records. |
Update fields |
Maps stream fields to objects fields for update. |
Key value fields
The key value fields are used to lookup an object. If no key value fields are specified, all incoming records are treated as new. If the records already exist you should get a database constraint error.
Option |
Description |
|---|---|
Model Field |
Model/Object field to do the comparison to |
Comparison |
Currently only supports "=,is null,is not null" |
Stream Field |
Stream field to use in the comparison to the Model Field. If a stream field isn't used, it is taken as a constant. For example 'customer', '=', 'false'. false is then taken as a constant. |
Key value field considerations
Key value field specifications should make use of constant values as much as possible to pre-filter the lookup data.
All rows matching the constant values in the key value field specification are read into memory at the start of the transformation. For example if you were loading the res.partner object for customers you may have had a key value lookup fields of:
Model Field |
Comparison |
Value |
|---|---|---|
customer |
= |
true |
ref |
= |
stream_ref_fld |
All res.partner objects where customer = true would be read into memory at the start of the transformation.
Each incoming row is matched against the remaining specification to find the matching row (In this example where ref = stream_ref_fld). If a row is found, the ID is recorded, if not,0 is sent through to the import function and a new record will be added.
The reason for pre-loading all data is to avoid a call to the server for every row, slowing the transformation down. If you have complex lookup requirements it is best to use the OpenERP Object Input step and do lookups using the "Stream Value Lookup" step.
Using the ID in the key field specification
If you use the ID field in the Model field, no lookup is done and the ID field is taken directly. For example if you had:
Model Field |
Comparison |
Value |
|---|---|---|
id |
= |
id_from_stream |
the value from id_from_stream would be mapped directly and no lookup will be done. This is useful in case you used the stream lookup or if you are updating existing data that you read using the OpenERP Object Input step.
Update field specification
Stream fields are mapped to object fields. Some fields are excluded from being updated. It includes:
- Child ids
- Function fields
- Read only fields
Updating related fields
If related fields are updated, make sure that the related object exist. For example the res.partner have a "phone" field that is related to the first res.partner.address record. If the record does not exist, it isn't created when you try and update the "phone" property. You update is simply ignored. If it does exist, the "phone" property will be updated on the first res.partner.address object. This is standard OpenERP behaviour when you use the import or write function to update a related field.
Updating many2many fields
A many2many field should be updated as comma separated list of ID fields. The new value will replace the old value. You have to read the old values and keep it in the final list if you don't want to lose the information. For example, if you want to add a user to a new group id=10], you need to get the old group ids [id=1,2,3] and add the group id you want to get a final list of ids [id=1,2,3,10]. If you don't, the user will be deleted from all groups and only belong to the group you selected [id=10].
Updating selection fields
Selection fields can be updated with the code or the description. The value will be corrected before it is sent to the import function.
FAQ
Why not use the create/write functions exclusively?
Because the OpenERP server currently only supports inserting/updating one record at a time using the create/write functions. Using the create/write functions, you need to make a server call for every row. By using the import function, you can submit a batch of data in one call. Using the import function is significantly faster than using the create/write functions. The OpenERP XML data load also uses the import function, probably for the same reason. The only time the create function is used, is when the object ID needs to be retrieved after update.