Unknown macro: {scrollbar}
How to use a PDI job to move a file into HDFS.
Prerequisites
In order to follow along with this how-to guide you will need the following:
- Hadoop
- Pentaho Data Integration
Sample Files
The sample data file needed for this guide is:
File Name |
Content |
Unparsed, raw weblog data |
Step-By-Step Instructions
Setup
Start Hadoop if it is not already running.
Create a Job to Put the Files into Hadoop
In this task you will load a file into HDFS.
Speed Tip
You can download the Kettle Job load_hdfs.kjb if you don't want to do every step
- Start PDI on your desktop. Once it is running choose 'File' -> 'New' -> 'Job' from the menu system or click on the 'New file' icon on the toolbar and choose the 'Job' option.
- Add a Start Job Entry: You need to tell PDI where to start the job, so expand the 'General' section of the Design palette and drag a 'Start' job entry onto the job canvas.
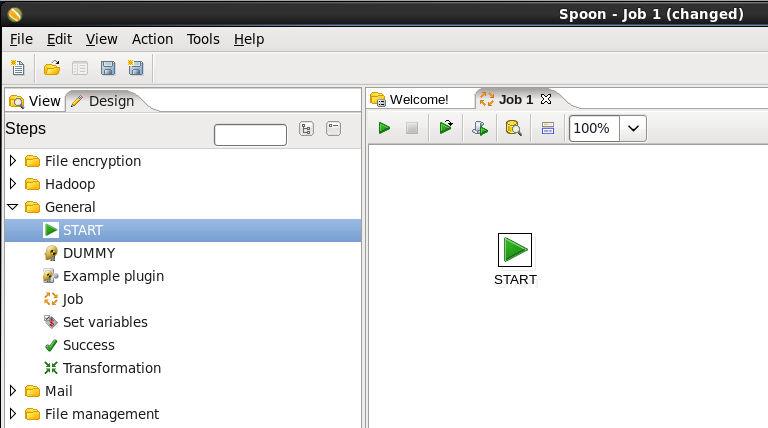
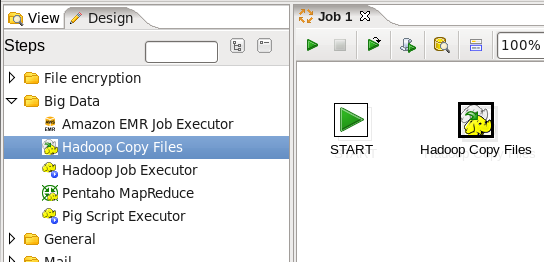
- Add a Copy Files Job Entry: You will copy files from your local disk to HDFS, so expand the 'Big Data' section of the Design palette and drag a 'Hadoop Copy Files' job entry onto the job canvas. Your canvas should look like this:
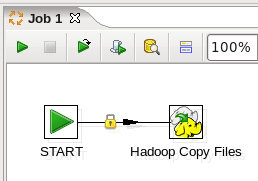
- Connect the Start and Copy Files Job Entries: Hover the mouse over the 'Start' node and a tooltip will appear.
 Click on the output connector (the green arrow pointing to the right) and drag a connector arrow to the 'Hadoop Copy Files' node. Your canvas should look like this:
Click on the output connector (the green arrow pointing to the right) and drag a connector arrow to the 'Hadoop Copy Files' node. Your canvas should look like this:
- Edit the Copy Files Job Entry: Double-click on the 'Hadoop Copy Files' node to edit its properties. Enter this information:
- File/Folder source(s): The folder containing the sample files you want to add to the HDFS.
- File/Folder destination(s): hdfs://<NAMENODE>:<PORT>/user/pdi/weblogs/raw
- Wildcard (RegExp): Enter ^.*\.txt
- Click the Add button to add the above entries to the list of files you wish to copy.
- Check the "Create destination folder" option to ensure that the weblogs folder is created in HDFS the first time this job is executed.
When you are done your window should look like this (your file paths may be different):
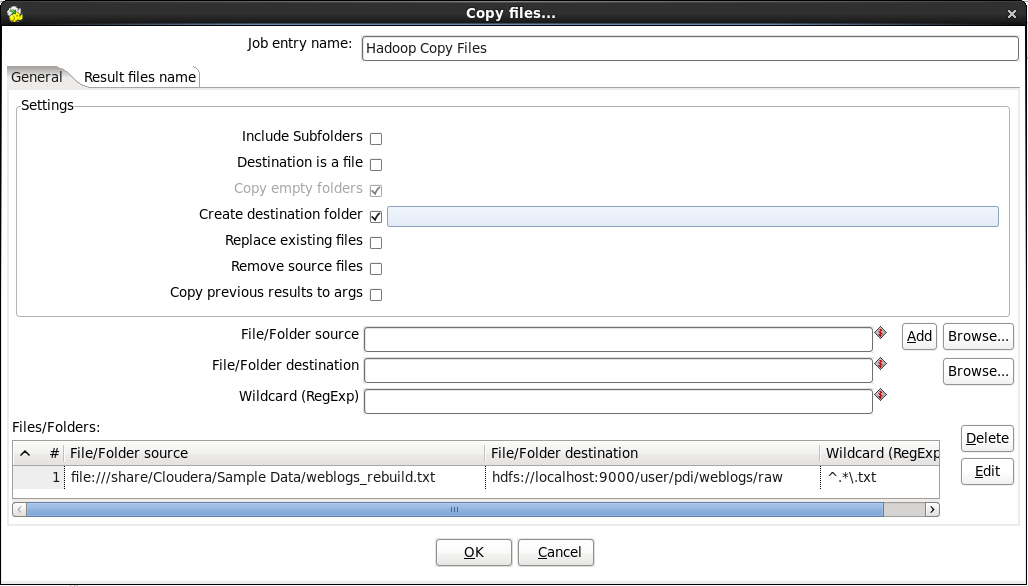
Click 'OK' to close the window.
- Save the Job: Choose 'File' -> 'Save as...' from the menu system. Save the transformation as 'load_hdfs.kjb' into a folder of your choice.
- Run the Job: Choose 'Action' -> 'Run' from the menu system or click on the green run button on the job toolbar. An 'Execute a job' window will open. Click on the 'Launch' button. An 'Execution Results' panel will open at the bottom of the PDI window and it will show you the progress of the job as it runs. After a few seconds the job should finish successfully:

If any errors occurred the job step that failed will be highlighted in red and you can use the 'Logging' tab to view error messages.
Check Hadoop
- Run the following command:
This should return:
hadoop fs -ls /user/pdi/weblogs/raw
-rwxrwxrwx 3 demo demo 77908174 2011-12-28 07:16 /user/pdi/weblogs/raw/weblog_raw.txtSummary
In this guide you learned how to copy local files into HDFS using PDI's graphical design tool. You can use this tool to put files into the HDFS from many different sources.
Troubleshooting
- Make sure you have the correct shim configured and that it matches your Hadoop cluster's distro and version.
- Problem: Hadoop copy files step creates an empty file in HDFS and hangs or never writes any data.
Check: The Hadoop client side API that Pentaho calls to copy files to HDFS requires that PDI has network connectivity to the nodes in the cluster. The DNS names or IP addresses used within the cluster must resolve the same relative to the PDI machine as they do in the cluster. When PDI requests to put a file into HDFS, the Name Node will return the DNS names (or IP address' depending on the configuration) of the actual nodes that the data will be copied to.
- Problem: Permission denied: user=XXXX, access=EXECUTE, inode="/user/pdi/weblogs/raw":raw:hadoop:drwxr-x---
When not using Kerberos security, the Hadoop API used by this step sends the username of the logged in user when trying to copy the file(s) regardless of what username was used in the connect field. To Change the user you must set the environment variable HADOOP_USER_NAME. You can modify spoon.bat or spoon.sh by changing the OPT variable:OPT="$OPT .... -DHADOOP_USER_NAME=HadoopNameToSpoof"
Unknown macro: {scrollbar}