...
In version 3.0 of Pentaho Data Integration we allow you to execute a job you defined on a (remote) slave server. This page explains how to set this up and what to look out for.
Basics
In a typical ETL setup, you might come across the need to fire off a job on a remote server somewhere. Version 3.0 of PDI is the first one to allow this.
Here is how you do it: you define a Slave Server in your job and specify the slave server on which you want to run the job on like this:
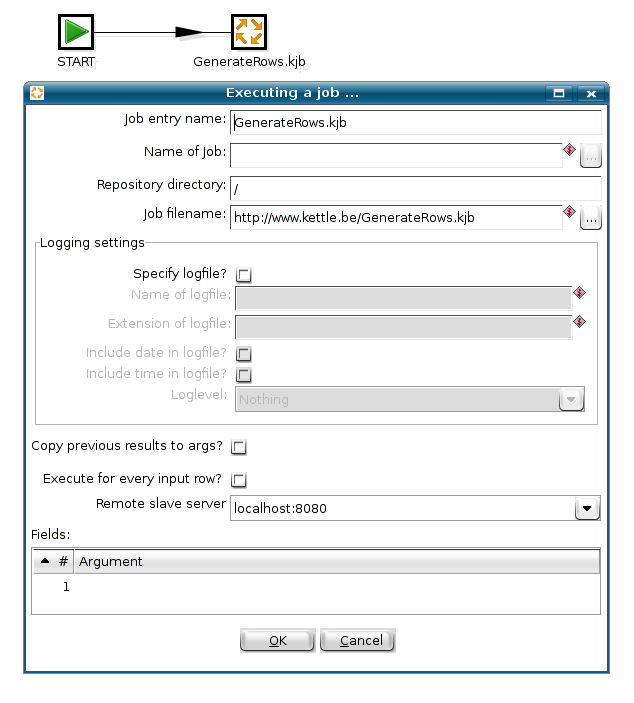
...
| Code Block |
|---|
zip:http://ww.foo.com/bar/bigjob.zip!/MainJob.kjb |
Repository access is not available on slave server
Because the repository login credentials where not yet sent over "the wire" we could not offer a solution for this problem in version 2.5.x.
Version 3.0.0 fixes this issue by passing the repository name, user name and password to the slave server.
Please note that the slave server has to be aware of the location of the repository. Normally, the file $HOME/.kettle/repositories.xml is referenced for this. However, you can also copy this file into the directory in which you started Carte (the local directory).
Even if you set this up correctly, verify that the slave server can reach the repository database over the network and that the repository database contains permissions for the slave server to access it.