Description
This step provides the ability to read data from any type of XML file using XPath specifications. For more information on XPath, see this tutorial: https://www.w3schools.com/xml/xpath_intro.asp or the W3C Recommendation: http://www.w3.org/TR/xpath
"Get Data From XML" can read data from 3 kind of sources (files, stream and url) in 2 modes (user can define files and urls at static mode or in a dynamic way). The following sample transformation will show you the differents options with this step :
| Code Block |
|---|
samples/transformations/GetXMLData - Differents Options.ktr |
Note for HTTP URL requests: You should be aware that this component will re-query the URL for each lookup request. Therefore if you are using this component to query a HTTP URL for an XML document, you should consider using the "Loop XPath" and "Prune path" parameters - these will help you avoid re-querying for the XML document. Also note that this component seems to make a HTTP HEAD request prior to the actual HTTP GET - if your XML document is a dynamic query (ASP/PHP/etc.), you should be aware that this HTTP HEAD request may result in an additional call to your URL.
Please see also the XML Input Stream (StAX) step that uses a completely different approach to solve use cases with very big and complex data stuctures and the need for very fast data loads.
Options
Files Tab
The files tab is where you define the location of the XML files from which you want to read. The table below contains options associated with the Files tab:
Option | Description |
|---|---|
Step Name | Name of the step; the name has to be unique in a single transformation. |
XML Source from field |
|
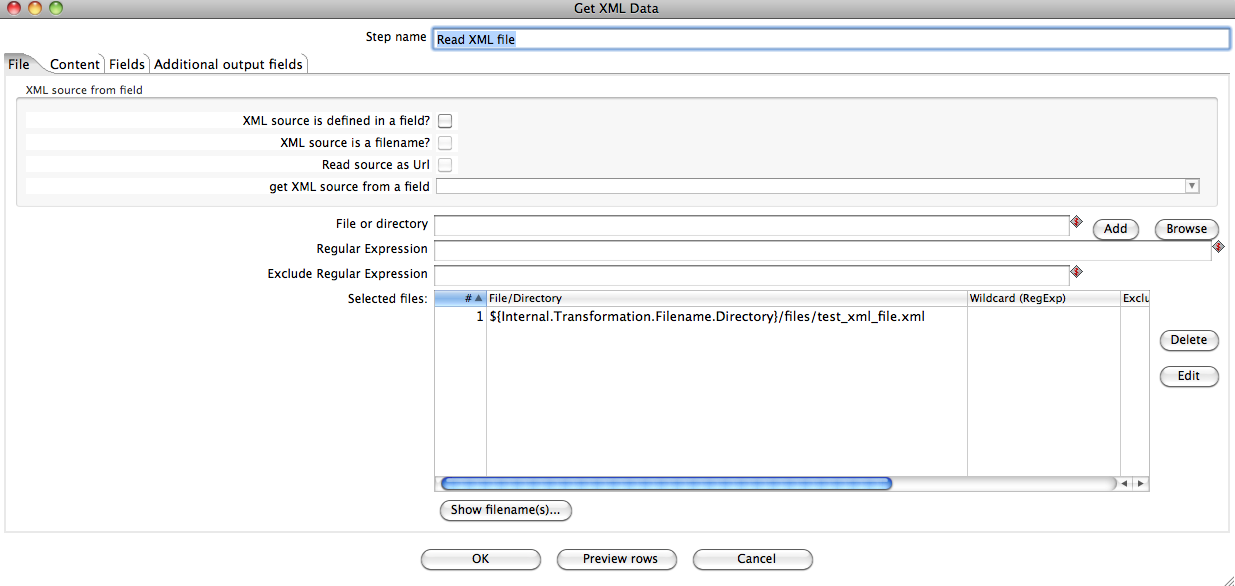
File or directory | Specifies the location and/or name of the input text file. Note: Click Add to add the file/directory/wildcard combination to the list of selected files (grid) below. |
Regular expression | Specifies the regular expression you want to use to select the files in the directory specified in the previous option. |
Selected Files | Contains a list of selected files (or wildcard selections) and a property specifying if file is required or not. If a file is required and it is not found, an error is generated;otherwise, the file name is skipped. |
Show filename(s)... | Displays a list of all files that will be loaded based on the current selected file definitions |
Content Tab
Option | Description |
|---|---|
Settings |
|
Additional fields |
|
Add to result filename |
|
Fields Tab
Option | Description |
|---|---|
Name | The name of the output field |
XPath | The path to the element node or attribute to read |
Element | The element type to read: Node or Attribute |
Type | The data type to convert to |
Format | The format or conversion mask to use in the data type conversion |
Length | The length of the output data type |
Precision | The precision of the output data type |
Currency | The currency symbol to use during data type conversion |
Decimal | The numeric decimal symbol to use during data type conversion |
Group | The numeric grouping symbol to use during data type conversion |
Trim type | The type of trimming to use during data type conversion |
Repeat | Repeat the column value of the previous row if the column value is empty (null) |
Metadata Injection Support
You can use the Metadata Injection supported fields with ETL Metadata Injection step to pass metadata to your transformation at runtime. The following Option and Value fields of the Get Data from XML step support metadata injection:
- Options: XML Source from Field, File and Directory, Regular Expression, Selected Files, Show Filenames, Settings, Additional Fields, and Add to Result Filename
- Values: Name, XPath, Element, Type, Format, Length, Precision, Currency, Decimal, Group, Trim Type, Short Filename, Extension, Size, Is Hidden, Last Modification, URI, and Root URI
Examples
Example 1 : basic example
This sample is also available in the distribution :
| Code Block |
|---|
samples/transformations/GetXMLData - Basic reading flat XML.ktr |
Data read:
| Code Block |
|---|
<Level1>
<Level2>
<Props>
<ObjectID>AAAAA</ObjectID>
<SAPIDENT>31-8200</SAPIDENT>
<Quantity>1</Quantity>
<Merkmalname>TX_B</Merkmalname>
<Merkmalswert> 600</Merkmalswert>
</Props>
<Props>
<ObjectID>AAAAA</ObjectID>
<SAPIDENT>31-8200</SAPIDENT>
<Quantity>3</Quantity>
<Merkmalname>TX_B</Merkmalname>
<Merkmalswert> 900</Merkmalswert>
</Props>
</Level2></Level1>
|
Options set:
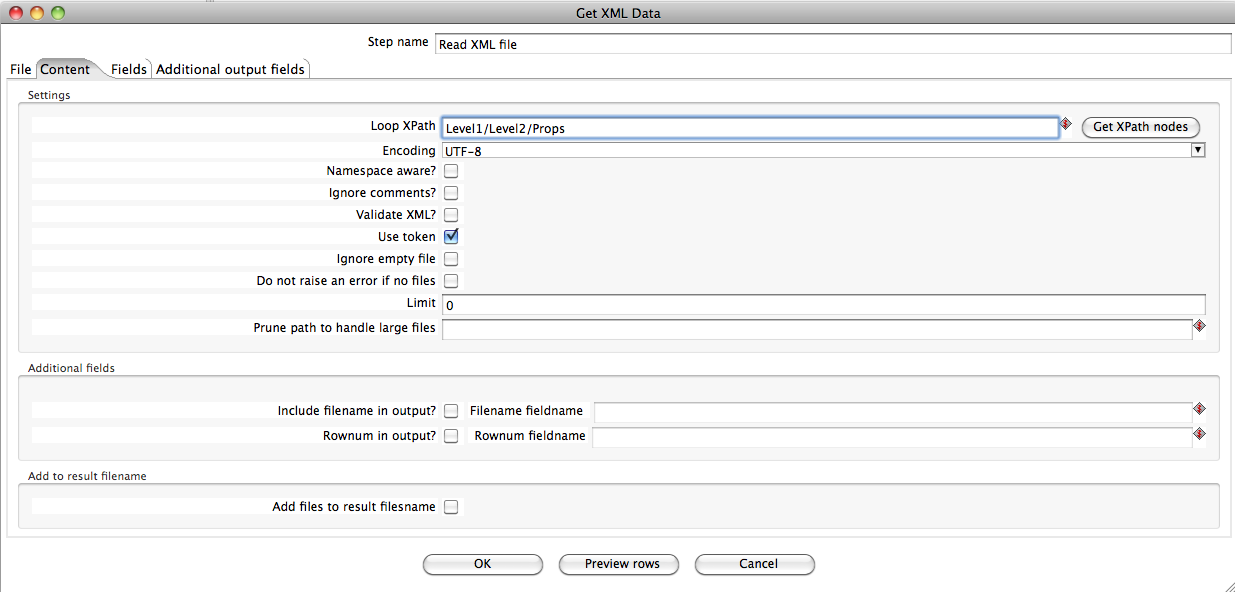
- Loop XPath : Level1/Level2/Props
- Encoding : UTF-8 (non supplied on purpose)
- Field XPaths:
- ObjectID
- SAPIDENT
- Quantity
- Merkmalname
- Merkmalswert
Screenshots:
File
Content
Example 2 :reading from parent nodes
This sample is also available in the distribution :
| Code Block |
|---|
samples/transformations/GetXMLData - Read parent children rows.ktr |
Data read:
| Code Block |
|---|
<database> <item id="111" clientName="Sven Boden"> <detail child_id="1"> <name>Bisoprolol</name> <amount>2</amount> </detail> <detail child_id="2"> <name>Aspirine</name> <amount>20</amount> </detail> </item> <item id="112" clientName="Gusia Jakobczyk"> <detail child_id="1"> <name>Libitor</name> <amount>1</amount> </detail> </item> </database> |
Options set:
In this case, we want to read data from looping node "database/item/detail". This allow us to have a row for each "database/item/detail" that kettle founds in the xml. However, we also want information from parent node "database/item", more to the point, the attributes there, for example the id.
- Loop XPath: database/item/detail
- Encoding : UTF-8 (non supplied on purpose)
- Field XPaths:
- ../@id : reads IDs 111, 112 (The ../ allows us to up one level, to the direct ancestor. The data will be repeated in rows of the same parent)
- @child_id : reads IDs 1, 2 and 1
- name
- amount
Note : @ is a shortcut to specify that you want an attribute.
Example 3 :how to use tokens
Let's consider the sample transformation :
| Code Block |
|---|
samples/transformations/GetXMLData - Differents Options.ktr |
In this sample, the first transformation 
uses tokens to parse the following XML file structure :
| Code Block |
|---|
<Session_header Code="xmltest"> <InfoSession> <InfoSessionData User="Username1"> <Data>Data1</Data> </InfoSessionData> </InfoSession> <InfoSession> <InfoSessionData User="Username2"> <Data>Data2</Data> </InfoSessionData> </InfoSession> <InfoSession> <InfoSessionData User="Username3"> <Data>Data3</Data> </InfoSessionData> </InfoSession> <Session> <SessionData> <Parameter> <User>Username1</User> <Password>password123</Password> </Parameter> <OutputData> <Step> <Error_Message>Please have transaction ID and related information ready. Timestamp : 20070731 01:50:06 Session : 0201</Error_Message> </Step> </OutputData> </SessionData> <SessionData> <Parameter> <User>Username2</User> <Password>password345</Password> </Parameter> <OutputData> <Step> <Error_Message>error occurred Timestamp : 20070731 01:53:25</Error_Message> </Step> </OutputData> </SessionData> <SessionData> <Parameter> <User>Username3</User> <Password>password567</Password> </Parameter> <OutputData> <Step> <Error_Message>Transaction Id :361163328</Error_Message> <Status>Processed according to contract/plan provisions</Status> </Step> </OutputData> </SessionData> </Session> </Session_header> |
We want to extract all SessionData, so the Loop Xpath will be Session_header/Session/SessionData. We want to get the followings fields : Code, User, Password, Status, Error_Message, Data. Thanks to Xpath, it's easy the return the five first fields. In fact, the last field (Data) is out of the Loop Xpath (InfoSession) and depends of the User. So first you have to go in InfoSession (../../InfoSession) and return Data for each User (<Data></Data>).
As we have previously the value for each User (see User field), we need to return Data for each User. The syntax is : ../../InfoSession/InfoSessionData[@User=the current user value]/Data. We have to find a way to notify to PDI using the value of a field in a Xpath expression : this is what tokens are used for. To use in our case the User value in an expression; we will write @_User- and the expression for the field Data will became ../../InfoSession/InfoSessionData[@User=@_User-]/Data. To finish do not forget to check "Use tokens" option.
Note: The tokenized field have to be defined previously and at this time, you can not use more than one token per field.